my general notes
有感
————– 之前电脑进水了,mac没法数据恢复,这页面所有的markdown都是本地hard push上去的,于是我丢失了我所有的笔记,html强扭markdown勉强保留了一些内容——
我的临阵磨枪总结
一些公式
1. PBR
GGX 分布函数
GGX 分布函数主要用于控制表面的微观粗糙度,高光形状如下:
$$
D_{GGX}(N, H) = \frac{\alpha^2}{\pi ((N \cdot H)^2 (\alpha^2 - 1) + 1)^2}
$$
其中:
- $ N $ 是表面法线。
- $ H $ 是半程向量(光源方向与视线方向的中间向量)。
- $ \alpha $ 是粗糙度参数。
ggx比phong复杂度更高
- 切比雪夫多项式
切比雪夫多项式,一种逼近方法,适用于特定区间(通常是 $ [-1, 1] $)的逼近。切比雪夫多项式 $ T_n(x) $ 是一组正交多项式,定义为
Phong 分布函数
Phong 分布函数使用一个指数 $ n $ 来控制光滑度。公式如下:
$$
D_{Phong}(N, H) = \frac{n + 2}{2\pi} (N \cdot H)^n
$$
其中:
- $ n $ 是高光反射指数,数值越高表示表面越光滑。
Blinn-Phong
Blinn-Phong氏光照模型是对Phong氏光照模型的改进,Phong模型在处理高光时会出现光照不连续的情况。当光源和视点位于同一个方向时,反射光线跟观察方向可能大于90度,反射光线的分量就被消除了,所以出现高光不连续的现象。Blinn-Phong模型在处理镜面反射时不使用观察方向和反射光线的夹角来计算,而是引入了一个新的向量:半程向量(Halfway vector)。半程向量其实很简单,就是入射光线向量L和观察方向V的中间位置(角平分线)。Blinn-Phong求高光亮度的时候使用半程向量和法向量的点积来决定高光亮度。Phong是用反射光线和视线向量的点积来求高光亮度。
Cook-Torrance BRDF
Cook-Torrance 是一个完整的BRDF模型,包含分布函数 $ D $、菲涅耳项 $ F $、几何遮挡项 $ G $。公式如下:
$$
f_r(L, V) = \frac{D(H) \cdot F(V, H) \cdot G(L, V, H)}{4(N \cdot L)(N \cdot V)}
$$
其中:
- $ L $ 是光源方向。
- $ V $ 是视线方向。
- $ N $ 是表面法线。
- $ H $ 是半程向量(光源方向与视线方向的中间向量)。
- $ D $ 是表面分布函数,例如可以使用 GGX 或 Phong 分布。
- $ F $ 是菲涅耳项,通常使用 Schlick 近似公式。
- $ G $ 是几何遮挡项,用于表示光线在微表面上的遮挡。
toon shader
漫反射(Diffuse Shading):通过法向量和光源方向的点积: $N \cdot L$ 来计算漫反射强度,然后使用 smoothstep 函数分段化这个值,使漫反射区域形成阶梯效果,不同亮度区间表现为不同颜色。
镜面高光(Specular Shading):利用法向量和半向量的点积: $N \cdot H$ 并应用 smoothstep 阶梯化高光强度,控制光滑度,产生离散的镜面反射效果,符合卡通风格。
边缘光(Rim Lighting):通过视角方向和法向量的点积计算边缘亮度,将高亮区域集中在物体轮廓,用 pow 和 smoothstep 调整边缘光的强度,使物体轮廓清晰、突出。
1 | |
2. render equation
$$
L_o(p, \omega_o) = L_e(p, \omega_o) + \int_{\Omega} f_r(p, \omega_i, \omega_o) L_i(p, \omega_i) (n \cdot \omega_i) d\omega_i
$$
- $L_o(p, \omega_o)$:点 $p$处沿视角方向 $\omega_o$的出射辐射亮度。
- $L_e(p, \omega_o)$:自发光项,表示点 $p$自身向方向 $\omega_o$发射的光。
- $f_r(p, \omega_i, \omega_o)$:BRDF(双向反射分布函数),描述光从入射方向 $\omega_i$到出射方向 $\omega_o$的反射行为。
- $L_i(p, \omega_i)$:点 $p$处从入射方向 $\omega_i$到达的入射辐射亮度。
- $n$:表面法线。
- $\omega_i$:入射方向。
- $d\omega_i$:微分立体角,用于积分。
3. 辐射度量学
- 辐射通量 (Radiant Flux)
$$
\Phi = \int_S \int_{\Omega} L(p, \omega) , (n \cdot \omega) , d\omega , dA
$$
- $\Phi $:辐射通量,表示在单位时间内通过某一表面的总能量(单位:瓦特)。
- $L(p, \omega) $:在点 ( p ) 处沿方向 ( \omega ) 的辐射亮度。
- $n $:表面法线。
- $d\omega $:微分立体角。
- $dA $:微分面积。
- 辐射亮度 (Radiance)
$$
L = \frac{d^2 \Phi}{dA \cdot d\omega \cdot \cos\theta}
$$
- $L $:辐射亮度,描述单位面积、单位立体角方向上的辐射强度。
- $d^2 \Phi $:微分辐射通量。
- $dA $:微分面积。
- $d\omega $:微分立体角。
- $\cos\theta $:入射角的余弦值,用于调整角度对亮度的影响。
辐照度 (Irradiance)
$$
E = \frac{d\Phi}{dA}
$$
- $E $:辐照度,单位面积上接收到的辐射能量密度。
- $d\Phi $:微分辐射通量。
- $dA $:微分面积。
零散概念
- 裁剪->Alpha->模板->深度
- 各向同性(Isotropic):指的是纹理在所有方向上都均匀采样的方式。简单的双线性(Bilinear)或三线性(Trilinear)滤波就属于各向同性滤波方式,它们在各个方向上的采样密度相同,但这种方式在斜向观看时会导致纹理细节丢失。
各向异性(Anisotropic):顾名思义,它在不同方向上采取不同的采样密度。对于视角倾斜的表面,各向异性滤波会在与视线垂直的方向上增加采样密度,保持纹理的清晰度。
描边
后处理描边(Screen-Space Outline)
概念:后处理描边是在场景渲染完成后,在屏幕空间(Screen-Space)中对图像进行处理。该方法通过深度缓冲和法线缓冲的差异来检测物体的边缘。
实现方式:
渲染场景时保存每个像素的深度值和法线信息。
通过检测邻近像素的深度值和法线方向差异来确定边缘位置。
在边缘处绘制描边颜色。
优点:适用于复杂场景,不受几何体的复杂程度影响,且不需多次绘制。Sobel 边缘检测
概念:Sobel 边缘检测是一种图像处理方法,常用于图像后处理阶段。通过计算图像的梯度来检测边缘。
实现方式:
渲染场景并生成深度和法线缓冲。
在后处理阶段应用 Sobel 算子计算梯度,检测图像中的边缘。
将边缘像素绘制成描边颜色。
优点:适用于动态场景,能够检测图像中的边缘信息。
缺点:对场景的深度和法线依赖较大,有可能产生伪边缘。
贝塞尔曲线
一阶贝塞尔曲线(线性贝塞尔曲线)
$$
B(t) = (1 - t) P_0 + t P_1
$$二阶贝塞尔曲线(抛物线)
$$
B(t) = (1 - t)^2 P_0 + 2(1 - t)t P_1 + t^2 P_2
$$三阶贝塞尔曲线(立方曲线)
$$
B(t) = (1 - t)^3 P_0 + 3(1 - t)^2 t P_1 + 3(1 - t)t^2 P_2 + t^3 P_3
$$
其中,$t \in [0, 1]$ 表示参数,$P_0, P_1, P_2, P_3$ 为控制点。
4.一般公式(n阶贝塞尔曲线)
$$
B(t) = \sum_{i=0}^{n} \binom{n}{i} (1 - t)^{n - i} t^i P_i
$$
其中,$\binom{n}{i}$ 是二项式系数。
graphic pipeline
渲染管线概述
渲染管线是将三维场景转换为二维图像的过程,通常由一系列步骤组成,每个步骤在图形渲染中都有特定的功能。整个流程可以分为以下主要阶段:
- 应用阶段(Application Stage)
- 几何处理阶段(Geometry Processing Stage)
- 光栅化阶段(Rasterization Stage)
- 像素处理阶段(Fragment Processing Stage)
- 输出合并阶段(Output Merging Stage)
1. 应用阶段(Application Stage)
功能:
- 场景管理:加载模型、纹理和创建场景图。
- 物理和动画计算:处理物体的运动、变形和碰撞检测。
- 视锥体裁剪(Frustum Culling):剔除视野外的物体以提高性能。
- 提交绘制指令:向渲染API(如OpenGL、DirectX)发送绘制命令。
要点:
- 这是CPU主导的阶段,主要负责准备渲染所需的数据。
- 优化此阶段可以减少GPU的负载,例如通过实例化减少绘制调用。
2. 几何处理阶段(Geometry Processing Stage)
功能:
- 顶点着色器(Vertex Shader):对每个顶点进行变换和光照计算。
- 模型变换:将物体从模型坐标系转换到世界坐标系。
- 视图变换:将世界坐标系转换到相机坐标系。
- 投影变换:将三维坐标转换为二维投影平面。
- 曲面细分着色器(Tessellation Shader,可选):细化几何体,提高曲面细节。
- 几何着色器(Geometry Shader,可选):可以生成或修改图元(如点、线、三角形)。
要点:
- 这是GPU开始介入的阶段,提供可编程性以实现各种视觉效果。
- 变换后的顶点用于后续的光栅化过程。
3. 光栅化阶段(Rasterization Stage)
功能:
- 图元组装:将顶点组装成基本图元(如三角形)。
- 裁剪:剔除不可见的部分,减少后续处理。
- 屏幕映射:将坐标转换到屏幕空间。
- 光栅化:将图元转换为片段(像素级别的潜在数据)。
要点:
- 光栅化是从矢量到像素的转换过程。
- 效率在此阶段非常关键,因为涉及大量数据处理。
4. 像素处理阶段(Fragment Processing Stage)
功能:
- 片段着色器(Fragment Shader):计算每个片段的最终颜色和深度值。
- 纹理映射:应用纹理到片段上。
- 光照计算:进行像素级的光照和阴影处理。
- 着色:应用材质和其他视觉效果。
- 片段测试和操作:
- 深度测试:确定片段是否被遮挡。
- 模板测试:用于复杂的图形效果,如镜像或剪裁。
- 混合:处理半透明效果,混合新旧像素颜色。
要点:
- 片段着色器提供高度的可编程性,影响最终图像质量。
- 优化此阶段可以显著提高渲染性能,特别是在高分辨率下。
5. 输出合并阶段(Output Merging Stage)
功能:
- 合并片段到帧缓冲区(Framebuffer):将通过测试的片段写入帧缓冲区。
- 后期处理:应用全屏效果,如抗锯齿、HDR、色彩校正等。
- 显示输出:将最终图像传递给显示设备。
要点:
- 最后的机会优化和调整图像质量。
- 后期处理可以极大地增强视觉效果,但也需要权衡性能。
unity 相关
GPU Instance
GPU 实例化则是通过让 GPU 接受一组相同的几何和材质数据,但可以用不同的变换矩阵或其他参数来区分每个实例。这样,CPU 只需一次提交,GPU 可以在一次 draw call 中渲染多个实例。
- Automatic Instancing: unity自动搞。
- ComputeBuffer 和 Shader Instancing:对于更复杂的实例化需求,可以使用 ComputeBuffer 和 Shader 中的实例化技术。这种方法需要在 Shader 中编写实例化的逻辑,并用 ComputeBuffer 存储实例的变换矩阵、颜色等信息,然后在 Shader 中读取和应用这些数据。这种方法适合需要动态改变实例参数的场景,比如实现不同的动画效果。
头发和皮肤
皮肤渲染通常使用 Subsurface Scattering (SSS) 技术,以模拟光在皮肤下层的散射,从而产生自然的肤色和细腻的质感。常用的模型包括 Blinn-Phong 和 Lambertian 反射模型,配合纹理贴图增强细节。
头发渲染则涉及到光线与发丝的交互,通常使用基于粒子的技术或光线追踪,以实现真实的光泽和透明效果。头发的材质通常用 Fresnel 方程来处理,确保在不同视角下反射光的变化,同时利用纹理和几何体模型来增加细节与复杂度。
风
6种不同类型的Motors
- Directional 平行风 (类似unity WindZone里的Directional)
- Omni 全向风 (类似unity里的Spherial)
- Vortex 旋涡,沿某个轴产生风
- Moving 运动发动机,锥形,可以理解成发动机在运动,产生风场是锥形扩散的
- Cylinder 圆柱的上下面可以大小不一样
- Pressure 直接就是压强
优化GPU利用:通过分离计算风速的各个分量(X、Y、Z方向),使得每个方向的计算都能并行进行,减少了等待时间,并利用了GPU的并行计算优势。
LOD的类型
- 离散LOD:最常见的LOD类型,使用明确分隔的几个模型级别。
- 连续LOD:使用算法在一个模型上动态增减细节,通常用于地形的渲染。
- 屏幕空间LOD:基于对象在屏幕上占用的像素数量来决定其细节级别,适用于大型场景渲染。
C++ 一些我不看就忘的概念
single instance
1 | |
unity 管线
内置渲染管线 (Built-in Render Pipeline)
特点:Unity 的传统渲染管线,易于使用,适合小型项目和快速开发。
优点:简单直观,支持大部分Unity内置功能。
缺点:灵活性有限,较难进行定制。
- 高清晰度渲染管线 (HDRP - High Definition Render Pipeline)
特点:专为高端图形和高性能平台设计,提供先进的视觉效果。
优点:支持物理基渲染(PBR)、实时光照、反射、体积光等高端特性。
缺点:对硬件要求较高,不适合低端设备。 - 轻量级渲染管线 (LWRP - Lightweight Render Pipeline)
特点:为移动平台和低端设备优化的渲染管线,性能优越。
优点:易于设置和使用,提供高效的性能表现。
缺点:视觉效果相对HDRP较弱,功能也有限。 - 通用渲染管线 (URP - Universal Render Pipeline)
特点:继承了LWRP,适用于各种平台,包括移动、PC和主机。
优点:灵活性高,易于优化,支持多种平台,同时保持较好的视觉效果。
缺点:在某些高级特性上可能不如HDRP。
选择建议
项目需求:根据项目规模和目标平台选择适合的管线。
硬件考虑:考虑目标用户的设备性能,选择适当的渲染管线以平衡画质和性能。
开发经验:如果团队有较多的图形开发经验,可以考虑使用HDRP进行深度定制。
PSO

Nsight
启动Nsight Graphics:
打开Nsight Graphics工具。
连接到DirectX应用程序:
选择 “New Capture” 启动应用程序,或者使用 “Attach to Process” 连接到已经运行的DirectX应用程序。
捕获帧(Frame Capture):
在应用程序中找到性能问题或瓶颈所在的场景。
点击Nsight界面上的 “Capture” 按钮,捕获当前帧的所有渲染调用和GPU活动。
分析捕获的帧:
使用帧分析工具查看每个Draw Call、Dispatch Call以及渲染管线的状态。
查看详细的着色器性能数据、资源使用情况(如纹理、缓冲区)以及API调用的执行时间。
优化步骤:
优化着色器:分析着色器代码,减少复杂计算,优化寄存器使用。
减少Draw Call:通过批处理和实例化减少Draw Calls。
调整资源管理:优化纹理大小、格式和访问模式,减少内存带宽消耗。
使用调试工具:
利用着色器调试和逐帧调试功能,查看渲染问题的细节,并优化代码逻辑。
重复分析与优化:
反复进行帧捕获、分析、优化,直至达到满意的性能水平。
PBF

******
每次收到面试,会发现自己很多问题很基本都已经忘记了,鉴于我这么差的记忆力,总结一份针对于我岗位的面经。
Overall, topic can seperate to:
- computer grpaphic
- C++,
- hlsl/directX12
- graphic card: CUDAROCm ROCm
- internet
# Computer graphic
# graphic pipeline
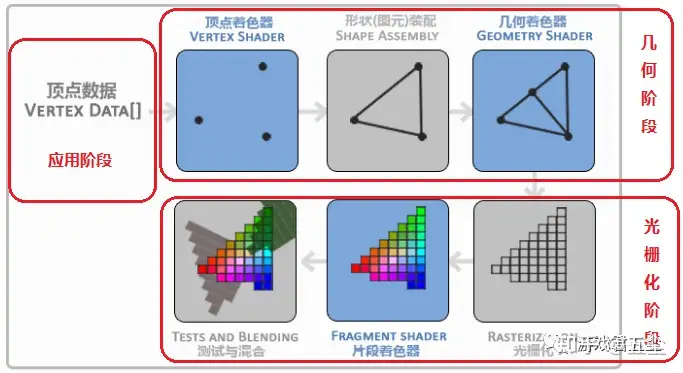
# Application 配置基础信息
在 CPU 完成,该阶段主要是在软件层面上执行的一些工作,包括空间加速算法、视锥剔除、碰撞检测、动画物理模拟等。大体逻辑是:执行视锥剔除,查询出可能需要绘制的图元并生成渲染数据,设置渲染状态和绑定各种 Shader 参数,调用 DrawCall,进入到下一个阶段,GPU 渲染管线。
- Geometry Processing 顶点着色、投影变换、裁剪和屏幕映射阶段。
- Rasterization 光栅化阶段是将图元离散化成片段的过程,其任务是找到需要绘制出的所有片段,包括三角形设定 (图元装配) 和三角形遍历阶段
- 像素处理阶段,给每一个像素正确配色,最后绘制出整幅图像,包括像素着色和合并阶段。
广以上 4 阶段如上,但是 directX12 中有更多。
- Input Assembler Stage
- Vertex Shader Stage
- Tessellation Stage
- Geometry Shader Stage
- Stream Output Stage
- Rasterization Stage
- Pixel Shader Stage
- Output Merger Stage
# 空间加速算法 (Spatial Acceleration)
# spatial partition vs object partition
- spatial paratition seperate space into non-overlapping regions
# 基于空间 (spatial partition)
- grid cell (最基本的划分)
- octTree (八叉树,通常以空间内最多两个物体结束) 简化版 KD tree
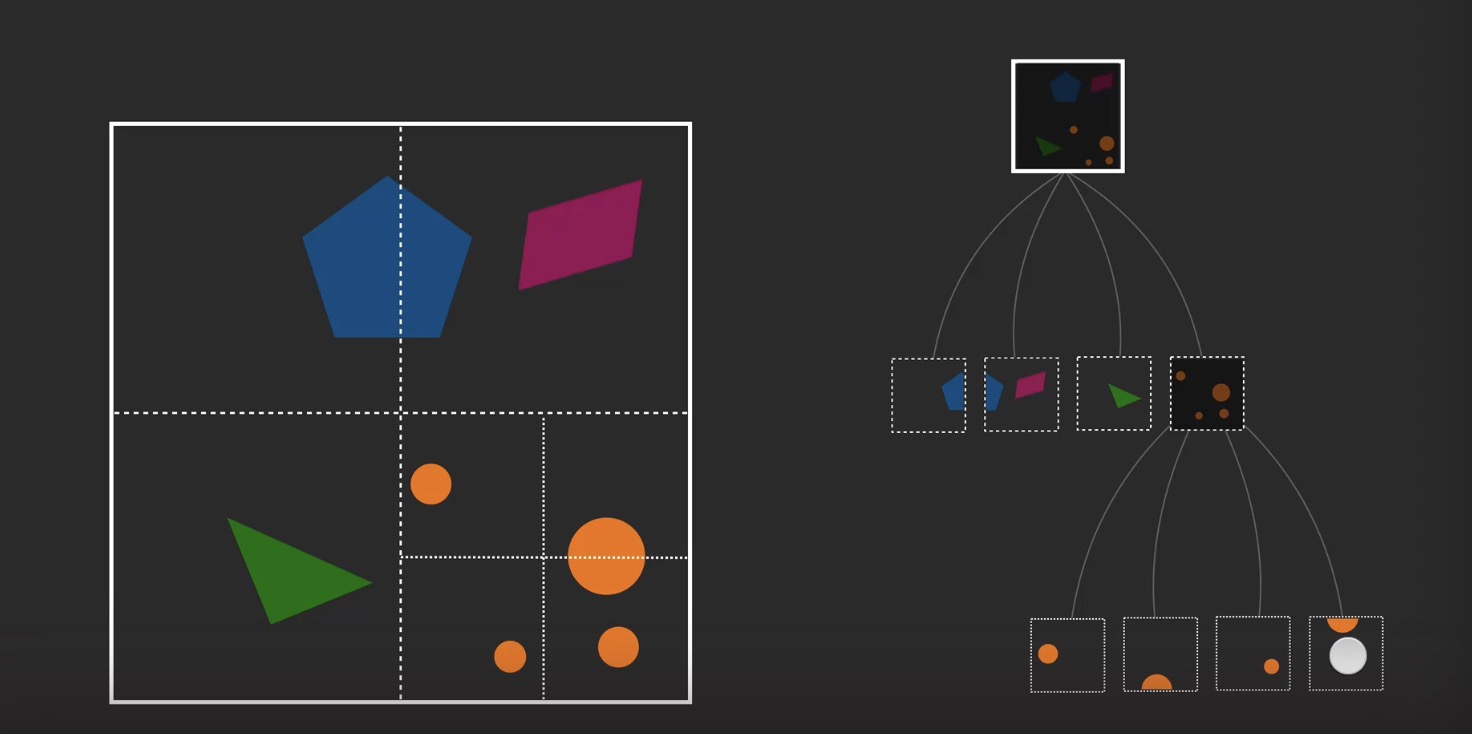
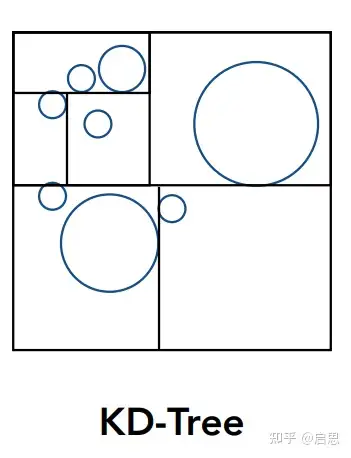
- KD tree 假设 k 纬空间内,有很多个物体。
# 基于物体
- AABB: box, 横平竖直的,Parallel xyz, 还有别的比如 Oriented Bounding Boxes (带角度的), 或者是球形的
- Uniform Grids
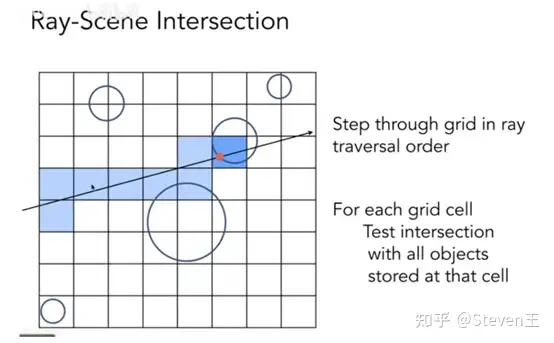
- BVH(Bounding Volume Hierarchy)

# 视锥剔除 (View frustum culling)
在经过 spatial acceleration 后物体有了边界。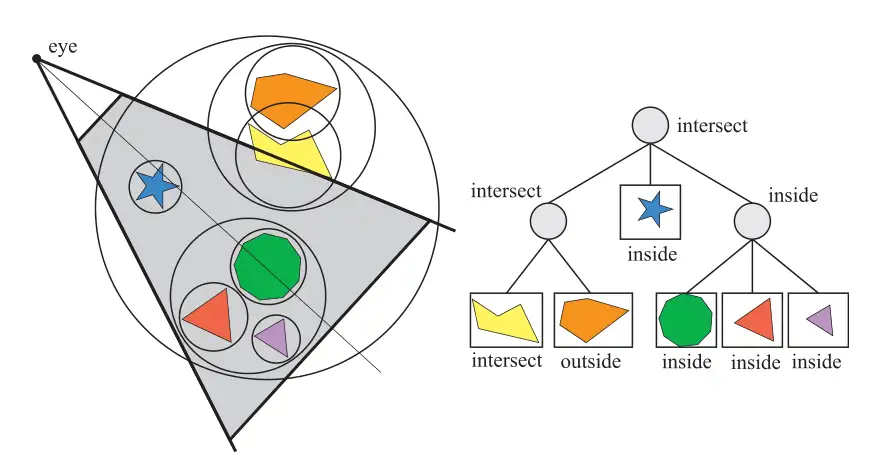
# shaders (着色器)
# 顶点着色器(Vertex Shader):
- 顶点着色器是渲染管线中的第一个阶段,负责处理每个顶点的信息。
- 它的主要功能是处理顶点数据(如坐标、颜色、纹理坐标等)并进行顶点的变换、裁剪和其他顶点级操作。
- 比如,它可以将顶点从模型空间(Model Space)转换到裁剪空间(Clip Space)。
# 曲面细分着色器(Tessellation Shader):
- 这类着色器通常用于根据某些准则对几何体进行细分,从而增加模型的复杂度和细节。
- 它包括曲面细分控制着色器(Hull Shader)和曲面细分评估着色器(Domain Shader)。
- 控制着色器决定如何细分几何体,而评估着色器处理细分后的顶点位置。
# 几何着色器(Geometry Shader):
- 几何着色器接受整个图元(如三角形、线、点)作为输入。
- 它可以生成新图元或者对输入的图元进行变换。
- 这个着色器可以用于实现一些复杂的效果,如体积阴影、粒子系统等。
# 片段着色器(Fragment Shader):
- 像素着色器处理图元光栅化后生成的每个片段。
- 它的主要任务是确定最终像素的颜色和其他属性(如深度、透明度等)。
- 这个阶段常用于实现各种像素级效果,如纹理映射、光照和阴影处理等。
# 计算着色器(Compute Shader):
- 计算着色器并非直接用于常规的图形渲染流程,而是用于处理广泛的非图形计算任务。
- 它们可以用来进行复杂的数学和物理计算,比如粒子系统的模拟、物理效果的计算等。
大量创建线程,计算不涉及直接渲染的任务,更加自由的数据访问或者处理数据,不受限于特定的阶段。
这段代码定义了一个计算着色器,它接受一个输入数组,并将每个元素的值增加 1。numthreads (1, 1, 1) 声明了每个线程组包含的线程数目。DTid 是当前线程的索引。
// SimpleComputeShader.hlsl
// 定义线程组的大小,这里设为1x1x1,可以根据需要调整。
[numthreads(1, 1, 1)]
void CSMain(uint3 DTid : SV_DispatchThreadID)
{
// 这里只是一个示例:每个线程将输入数组的对应值增加1
data[DTid.x] += 1;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
ID3DBlob* csBlob = nullptr;
D3DCompile(shaderSource, strlen(shaderSource), nullptr, nullptr, nullptr, "CSMain", "cs_5_0", 0, 0, &csBlob, nullptr);
`</pre>
1. 创建计算管线状态对象<pre>`D3D12_COMPUTE_PIPELINE_STATE_DESC psoDesc = {};
psoDesc.CS = {reinterpret_cast<BYTE*>(csBlob->GetBufferPointer()), csBlob->GetBufferSize()};
device->CreateComputePipelineState(&psoDesc, IID_PPV_ARGS(&pipelineState));
`</pre>
1. 创建并绑定资源<pre>`// 创建缓冲区资源并上传数据
D3D12_RESOURCE_DESC bufferDesc = CD3DX12_RESOURCE_DESC::Buffer(dataSize);
ID3D12Resource* buffer;
device->CreateCommittedResource(&heapProperties, D3D12_HEAP_FLAG_NONE, &bufferDesc, D3D12_RESOURCE_STATE_COPY_DEST, nullptr, IID_PPV_ARGS(&buffer));
D3D12_SUBRESOURCE_DATA bufferData = {};
bufferData.pData = data;
bufferData.RowPitch = dataSize;
bufferData.SlicePitch = bufferData.RowPitch;
UpdateSubresources(commandList, buffer, uploadBuffer, 0, 0, 1, &bufferData);
// 设置计算根签名和描述符
commandList->SetPipelineState(pipelineState);
commandList->SetComputeRootSignature(rootSignature);
commandList->SetComputeRootShaderResourceView(0, buffer->GetGPUVirtualAddress());
commandList->Dispatch(2, 2, 1);
`</pre>
## [#](#light-mapping光照贴图) light mapping (光照贴图)
## [#](#光照模型illumination-model) 光照模型 (illumination model)
### [#](#局部光照模型local-illumination-model) 局部光照模型 (local illumination model)
仅处理光源直接照射物体表面,不考虑其他反射。
* Lambert reflectance model: 所有方向上均匀的散射光,不考虑 viewpoint, 所以没有 specular highlight.
### [#](#全局光照模型global-illumination-model) 全局光照模型 (global illumination model)
## [#](#ray-tracing) ray tracing
## [#](#render-equation) render equation

## [#](#deferred-rendering) deferred rendering
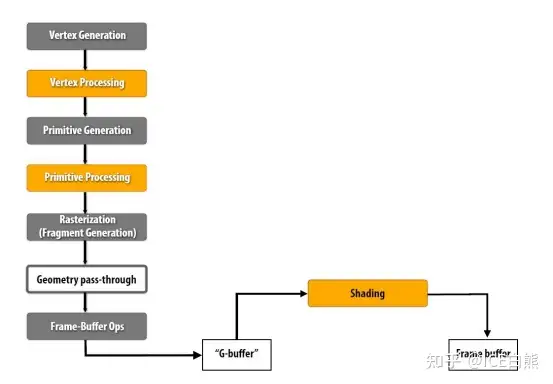
### [#](#forward-rendering) forward rendering
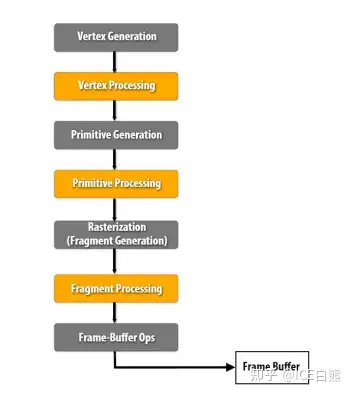
Forward Rendering: 在场景中我们根据所有光源照亮一个物体,之后再渲染下一个物体,以此类推
drawback: 因为大部分片段着色器的输出都会被之后的输出覆盖。
Deferred rendering 本质就是 defer 计算大的比如光照放到最后处理。
* one pass:

* second pass(lighting pass):
深度测试已经完毕,针对像素处理光照,而不是几何体。
drawback:
1. 消耗大量显存
2. 不支持混色 (blending) 即使 Alpha 通道或混合信息整合进 G-buffer,这通常会导致需要更多的带宽和内存,进而影响渲染性能。同时,混合操作(如 Alpha blending)通常需要多次读写同一个像素,这在延迟渲染的光照计算中是低效的。
1. 使用前向渲染处理透明物体:在使用延迟渲染处理场景的不透明部分后,再用前向渲染方式渲染透明物体。
2. 混合延迟渲染:结合使用延迟和前向渲染技术,例如,将透明效果或特定的光照效果保留在前向渲染路径中处理。
渲染顺序问题:延迟渲染通常将几何信息渲染到几何缓冲区中,然后根据光照信息在合成阶段进行像素合成。然而,透明物体需要按照深度顺序进行渲染,即先渲染远处的物体再渲染近处的物体,以保证正确的透明效果。这种渲染顺序的要求与延迟渲染的工作方式不太相符,需要额外的处理来实现正确的透明效果。
## [#](#shadow) shadow
* Lightmap: 沿着光源方向 bake 一个物体,offline rendering, 把结果放在 texture map。缺点只能放 diffuse,没法放 specular。并且没法动态阴影。
* Shadowmap: two pass, 光源的位置渲染一遍场景
第一个 pass,切换到以光源为视点的观察坐标系中,利用帧缓冲生成一张深度图 DepthMap
第二个 pass,正常渲染,对渲染的每一个 fragment 做可见性判断,得到一个非零即一的 visibility
将 shading point 通过第一个 pass 的变换得到的深度值和 epthMap 中记录的对应位置的深度值作比较
如果 DepthMap 中记录的值小,说明当前的点对光源不可见,visibility=0
否则 visibility=1
用 visibility 乘上当前点的直接光照,进行遮蔽效果
在实现上可以使用定向光做平行投影生成 DepthMap,也可以使用点光源做透视投影生成 DepthMap
* pcf(percentage closer filtering)本是用于做抗锯齿的算法,后常被用于软阴影的实现。pcf 的做法:在取 shading point 到光源的距离与 shadow map 进行比较时,不仅仅只取一个点,而是取周围范围的点,多次取平均,得到 visbility 值。例如周围九个点比较结果分别为:1,0,1,1,0,1,1,1,0,那么可见性即为 0.667。
* pcss(percentage closer soft shadow):我们知道往往阴影的接收物与投射物的距离越近,则阴影越硬,反之,阴影就越 “软”,pcss 正是基于这个思路去实现的。
* vsm(variance soft shadow mapping):本质上可以理解为是一种对 pcss 的加速,避免了第一步和第三步中的采样。用切比雪夫测试的方式直接判断当前深度在区域范围内排序的百分比,相当于我们就直接得到了 visbility 值,这样的做法避免了大量的采样,加速了整个过程。
* sdf 阴影:如下图所示,简单来说,是从 shading point 出发沿着灯光方向进行 ray marching,可以根据 sdf 提供的距离信息进行步进 step 优化,最终得到一个安全角度,该安全角度越小,则越暗,安全角度越大,则越亮。
### [#](#csm) CSM:
是一种用于在大范围场景中生成高质量阴影的技术。它通过将场景分割成多个级联区域,每个区域使用单独的阴影贴图来提高阴影的细节和分辨率。
1. 分割视锥体:
将摄像机的视锥体沿深度方向分割成多个区间(级联)。
每个级联区间对应一个不同的深度范围,这样可以在近处使用高分辨率的阴影贴图,在远处使用低分辨率的阴影贴图。
2. 计算每个级联的正交投影矩阵:
对每个级联区间,计算出包含该区间的正交投影矩阵,以便生成阴影贴图。
需要考虑光源方向,以确定正交投影的范围和位置。
3. 渲染阴影贴图:
对每个级联区间,从光源的视角渲染场景深度,生成对应的阴影贴图。
这些阴影贴图记录了场景中各个物体的深度信息。
4. 应用阴影贴图:
在主渲染通道中,根据摄像机视角,将不同级联的阴影贴图应用到场景中。
使用多个级联阴影贴图可以在近处保留细节,并在远处节省计算资源。
5. 处理阴影边界:
为了避免级联之间的明显边界,通常使用过渡区或模糊处理。
通过对相邻级联区域的阴影贴图进行平滑过渡,可以减少视觉上的突兀感。
## [#](#pbr) PBR
物理基础渲染(Physically Based Rendering,简称 PBR)是一种更加逼真地模拟光照和材质的渲染方法。PBR 基于物理学原理,使得渲染结果更加一致和真实。PBR 的核心思想是通过模拟光线和材质的物理交互来生成图像。
### [#](#pbr概念) PBR 概念
### [#](#1-brdf双向反射分布函数) 1. **BRDF(双向反射分布函数)**
BRDF 描述了光线如何从一个表面反射出去。PBR 使用物理上正确的 BRDF 来计算反射光线的方向和强度。常见的 BRDF 模型包括 Lambertian(漫反射)和 Cook-Torrance(镜面反射)。
### [#](#2-能量守恒) 2. **能量守恒**
PBR 保证了能量守恒,即材质反射的光量不会超过入射的光量。这一原则确保了材质在不同光照条件下都能表现得一致。
### [#](#3-微表面理论) 3. **微表面理论**
微表面理论假设一个表面由许多微小的镜面组成。这些微小的镜面随机分布,使得光线以不同角度反射,从而形成材质的粗糙度和高光特性。
### [#](#pbr-的主要参数) PBR 的主要参数
#### [#](#1-albedo反照率) 1. **Albedo(反照率)**
Albedo 是材质的基本颜色,表示在没有光照影响下的颜色。它不包含阴影、镜面反射等因素。
#### [#](#2-metalness金属性) 2. **Metalness(金属性)**
Metalness 参数定义材质的金属特性。金属材质具有高反射率和无透射率,反照率通常接近黑色。非金属材质则具有较低的反射率和一定的透射率。
#### [#](#3-roughness粗糙度) 3. **Roughness(粗糙度)**
Roughness 描述了表面的光滑程度。低粗糙度的表面光滑且反射清晰,高粗糙度的表面则粗糙且反射模糊。
#### [#](#4-normal-map法线贴图) 4. **Normal Map(法线贴图)**
法线贴图用于模拟细节纹理和凹凸效果,影响光线的反射方向,增加视觉细节。
#### [#](#5-ambient-occlusion环境光遮蔽) 5. **Ambient Occlusion(环境光遮蔽)**
环境光遮蔽用于模拟由于遮挡导致的局部阴影效果,增强视觉深度。
### [#](#pbr-工作流程) PBR 工作流程
1. **定义材质属性**
使用 Albedo、Metalness、Roughness 等参数来定义材质的物理特性。
2. **光照计算**
通过光照模型(如直接光源、环境光等)计算每个像素的光照强度。
3. **BRDF 计算**
根据 BRDF 模型和材质参数,计算光线在表面上的反射。
4. **合成最终图像**
将光照计算结果和材质反射计算结果合成,生成最终的渲染图像。
### [#](#cook-torrance) Cook-Torrance
* 计算微表面分布函数(D):选择适当的分布模型(如 GGX),根据表面粗糙度计算微表面分布。
* 计算几何遮蔽 / 阴蔽函数(G):选择几何函数(如 Schlick-GGX),根据表面粗糙度和光照角度计算遮蔽和阴蔽效果。
* 计算菲涅耳方程(F):使用 Schlick 近似,根据入射角和材料的折射率计算菲涅耳反射。
* 组合以上组件:将 D、G 和 F 结合起来,计算最终的反射和折射强度。
#### [#](#cook-torrance-模型的优点) Cook-Torrance 模型的优点
* 物理准确性:考虑了微表面的结构和光的物理特性,能够生成高度真实的反射和折射效果。
* 一致性:在不同光照条件下表现一致,使得材质在不同场景中具有一致的视觉效果。
* 灵活性:可以通过调整微表面分布函数、几何函数和菲涅耳方程的参数来模拟不同类型的材质,如金属、塑料等。
## [#](#mvp) MVP
### [#](#mvp-矩阵公式推导) MVP 矩阵公式推导
1. **模型矩阵 (Model Matrix, $M$)**
模型矩阵将对象坐标变换到世界坐标系。假设对象有一个平移变换和一个旋转变换,模型矩阵可以表示为:
$$
M = T \cdot R
$$
其中 $T$ 是平移矩阵,$R$ 是旋转矩阵。具体形式如下:
- 平移矩阵 $T$:
$$
T = \begin{bmatrix}
1 & 0 & 0 & x \\
0 & 1 & 0 & y \\
0 & 0 & 1 & z \\
0 & 0 & 0 & 1
\end{bmatrix}
$$
- 旋转矩阵 $R$(例如绕 $z$ 轴旋转):
$$
R = \begin{bmatrix}
\cos \theta & -\sin \theta & 0 & 0 \\
\sin \theta & \cos \theta & 0 & 0 \\
0 & 0 & 1 & 0 \\
0 & 0 & 0 & 1
\end{bmatrix}
$$
2. **视图矩阵 (View Matrix, $V$)**
视图矩阵将世界坐标变换到相机坐标系。假设相机位置为 $\mathbf{C} = (c_x, c_y, c_z)$,看向目标 $\mathbf{T} = (t_x, t_y, t_z)$,相机的上向量为 $\mathbf{U} = (u_x, u_y, u_z)$。
首先计算相机的三个基向量:
$$
\mathbf{z} = \frac{\mathbf{C} - \mathbf{T}}{|\mathbf{C} - \mathbf{T}|}
$$
$$
\mathbf{x} = \frac{\mathbf{U} \times \mathbf{z}}{|\mathbf{U} \times \mathbf{z}|}
$$
$$
\mathbf{y} = \mathbf{z} \times \mathbf{x}
$$
视图矩阵 $V$:
$$
V = \begin{bmatrix}
x_x & x_y & x_z & -(\mathbf{x} \cdot \mathbf{C}) \\
y_x & y_y & y_z & -(\mathbf{y} \cdot \mathbf{C}) \\
z_x & z_y & z_z & -(\mathbf{z} \cdot \mathbf{C}) \\
0 & 0 & 0 & 1
\end{bmatrix}
$$
3. **投影矩阵 (Projection Matrix, $P$)**
投影矩阵将相机坐标系变换到裁剪坐标系。以透视投影为例,设视锥体的参数为近剪裁面 $n$,远剪裁面 $f$,视角 $\theta$,宽高比 $a$。
透视投影矩阵 $P$:
$$
P = \begin{bmatrix}
\frac{1}{a \tan \frac{\theta}{2}} & 0 & 0 & 0 \\
0 & \frac{1}{\tan \frac{\theta}{2}} & 0 & 0 \\
0 & 0 & \frac{f+n}{n-f} & \frac{2fn}{n-f} \\
0 & 0 & -1 & 0
\end{bmatrix}
$$
4. **MVP 矩阵 (Model-View-Projection Matrix, $MVP$)**
最终的 $MVP$ 矩阵将对象坐标变换到裁剪坐标系:
$$
MVP = P \cdot V \cdot M
$$
## [#](#降低drawcall) 降低 drawCall
通过合并几何体、使用实例化渲染、纹理图集、批处理等技术,可以有效地减少 Draw Call 的数量,从而提升渲染性能。在 DirectX 中,实现这些技术需要对渲染管线和资源管理有深入的理解。
### [#](#合并几何体geometry-merging) 合并几何体(Geometry Merging)
将多个小的几何体合并成一个大的几何体,可以减少绘制调用的数量。例如,将多个相邻的地形块或相似的物体合并为一个网格。
### [#](#实例化渲染instanced-rendering) 实例化渲染(Instanced Rendering)
对于多个相同的物体,可以使用实例化渲染。实例化渲染允许你一次性绘制多个相同的物体,只需一次绘制调用,但可以通过不同的变换矩阵来修改每个实例的外观。
<pre>`// 示例代码:设置实例化渲染的变换矩阵
D3D11_BUFFER_DESC bufferDesc = {};
bufferDesc.Usage = D3D11_USAGE_DEFAULT;
bufferDesc.ByteWidth = sizeof(InstanceData) * numInstances;
bufferDesc.BindFlags = D3D11_BIND_VERTEX_BUFFER;
D3D11_SUBRESOURCE_DATA initData = {};
initData.pSysMem = instanceData;
ID3D11Buffer* instanceBuffer;
device->CreateBuffer(&bufferDesc, &initData, &instanceBuffer);
// 绑定实例缓冲区
UINT strides[2] = { sizeof(Vertex), sizeof(InstanceData) };
UINT offsets[2] = { 0, 0 };
ID3D11Buffer* buffers[2] = { vertexBuffer, instanceBuffer };
context->IASetVertexBuffers(0, 2, buffers, strides, offsets);
// 绘制调用
context->DrawInstanced(vertexCount, instanceCount, 0, 0);
`</pre>
### [#](#使用纹理图集texture-atlas) 使用纹理图集(Texture Atlas)
将多个纹理合并到一个大纹理中,减少纹理切换。这可以显著减少绘制调用和状态切换的开销。
### [#](#批处理batching) 批处理(Batching)
将具有相同材质和渲染状态的物体进行批处理。批处理可以将多个小的绘制调用合并成一个更大的绘制调用。
### [#](#动态管理资源dynamic-resource-management) 动态管理资源(Dynamic Resource Management)
合理使用动态资源更新机制,将多次小的更新合并为一次大的更新。例如,使用动态顶点缓冲区和索引缓冲区。
### [#](#使用多重索引缓冲区multi-index-buffers) 使用多重索引缓冲区(Multi-Index Buffers)
通过多重索引缓冲区来减少顶点缓冲区的切换,从而减少绘制调用。
### [#](#减少状态改变state-changes) 减少状态改变(State Changes)
尽量减少渲染状态(如混合状态、深度状态、光栅化状态等)的改变。尽可能地将相同状态的绘制调用集中在一起。
### [#](#使用更高效的资源绑定方式) 使用更高效的资源绑定方式
例如,DirectX 12 引入了描述符表(Descriptor Tables)和根签名(Root Signatures),可以更高效地管理资源绑定。
示例代码:批处理和实例化渲染结合
<pre>`struct InstanceData {
XMMATRIX worldMatrix;
};
std::vector<InstanceData> instances;
// 准备实例数据
for (int i = 0; i < numInstances; ++i) {
InstanceData instance;
instance.worldMatrix = XMMatrixTranslation(i * 2.0f, 0.0f, 0.0f);
instances.push_back(instance);
}
// 创建实例缓冲区
D3D11_BUFFER_DESC instanceBufferDesc = {};
instanceBufferDesc.Usage = D3D11_USAGE_DYNAMIC;
instanceBufferDesc.ByteWidth = sizeof(InstanceData) * numInstances;
instanceBufferDesc.BindFlags = D3D11_BIND_VERTEX_BUFFER;
instanceBufferDesc.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;
D3D11_SUBRESOURCE_DATA instanceData = {};
instanceData.pSysMem = instances.data();
ID3D11Buffer* instanceBuffer;
device->CreateBuffer(&instanceBufferDesc, &instanceData, &instanceBuffer);
// 绘制实例
UINT strides[2] = { sizeof(Vertex), sizeof(InstanceData) };
UINT offsets[2] = { 0, 0 };
ID3D11Buffer* buffers[2] = { vertexBuffer, instanceBuffer };
context->IASetVertexBuffers(0, 2, buffers, strides, offsets);
context->DrawInstanced(vertexCount, numInstances, 0, 0);
`</pre>
**深入解析PBR中的BRDF模型:GGX(Trowbridge-Reitz)、Lambertian、Cook-Torrance**
在物理基础渲染(PBR)中,双向反射分布函数(BRDF)是描述光与材质相互作用的核心组件。不同的BRDF模型通过数学公式模拟不同类型的光反射特性,以实现逼真的视觉效果。本文将具体讲解三种常用的BRDF模型:GGX(Trowbridge-Reitz)、Lambertian、Cook-Torrance,探讨它们的物理意义、数学表达及在PBR中的应用。
---
### 一、Lambertian反射模型
**1. 物理意义**
Lambertian模型描述的是理想的漫反射表面,即表面在各个方向上反射光线的强度相同,不依赖于观察方向。这种模型适用于粗糙表面,如磨砂玻璃、未打磨的木材等,能够模拟光线在粗糙表面上的随机散射。
**2. 数学表达**
Lambertian反射的BRDF公式如下:
$f_r(\omega_i, \omega_o) = \frac{\rho}{\pi} $
其中:
- $f_r$是BRDF。
- $\rho$是反射率(Albedo),表示表面反射光的比例。
- $\pi$是常数,保证能量守恒。
**3. 特点与应用**
- **能量守恒**:由于反射率被除以π,确保反射光的总能量不超过入射光。
- **方向无关性**:反射光强度与出射方向无关,适用于理想漫反射表面。
- **计算简便**:公式简单,计算效率高,常用于基础材质的渲染。
**4. PBR中的作用**
Lambertian模型作为最基础的漫反射模型,在PBR中常与镜面反射模型结合使用,用于描述非金属材质的漫反射部分。尽管它无法准确模拟微表面结构引起的细节,但其简单性使其在许多场景中仍然有效。
---
### 二、Cook-Torrance反射模型
**1. 物理意义**
Cook-Torrance模型是一种微表面BRDF模型,旨在更精确地模拟光在微观表面结构上的反射行为。该模型考虑了微表面的粗糙度、法线分布和几何遮挡等因素,能够模拟出真实世界中复杂的光反射现象,如金属表面的高光和镜面反射。
**2. 数学表达**
Cook-Torrance模型的BRDF公式如下:
\[ f_r(\omega_i, \omega_o) = \frac{D(h) \cdot F(\omega_i, h) \cdot G(\omega_i, \omega_o)}{4 (\omega_i \cdot n) (\omega_o \cdot n)} \]
其中:
- $h = \frac{\omega_i + \omega_o}{\|\omega_i + \omega_o\|}$是半程向量。
- $D(h)$是法线分布函数(NDF),描述微表面法线的分布。
- $F(\omega_i, h)$是菲涅尔项,描述入射光在半程向量上的反射比例。
- $G(\omega_i, \omega_o)$是几何遮挡函数,描述微表面之间的遮挡关系。
- $n$是表面法线。
**3. 组成部分详解**
- **法线分布函数(D)**:常用GGX(Trowbridge-Reitz)作为D函数,描述微表面法线的分布密度。
$$ D_{GGX}(h) = \frac{\alpha^2}{\pi \left[ (\omega \cdot h)^2 (\alpha^2 - 1) + 1 \right]^2} $$
其中,$\alpha$表示粗糙度参数。
- **菲涅尔项(F)**:使用Schlick近似公式计算:
$$ F(\omega_i, h) = F_0 + (1 - F_0) (1 - \omega_i \cdot h)^5 $$
其中,$F_0$是在法线方向上的菲涅尔反射率。
- **几何遮挡函数(G)**:常用Smith的几何遮挡函数:
\[ G(\omega_i, \omega_o) = G_1(\omega_i) \cdot G_1(\omega_o) \]
\[ G_1(\omega) = \frac{2 (\omega \cdot n)}{\omega \cdot n + \sqrt{\alpha^2 + (1 - \alpha^2)(\omega \cdot n)^2}}} \]
**4. 特点与应用**
- **物理准确性**:综合考虑了微表面法线分布、菲涅尔反射和几何遮挡,能够更真实地模拟镜面反射。
- **可调节性**:通过调整粗糙度参数$\alpha$,可以控制高光的锐利程度和扩散程度。
- **广泛应用**:适用于金属和高光材质的渲染,能够表现出复杂的反射特性。
**5. PBR中的作用**
Cook-Torrance模型是PBR中常用的镜面反射模型,尤其在处理金属材质时表现出色。结合Lambertian模型,它能够同时描述漫反射和镜面反射部分,提供更全面的光反射模拟。
---
### 三、GGX(Trowbridge-Reitz)反射模型
**1. 物理意义**
GGX(Trowbridge-Reitz)模型是一种改进的法线分布函数(NDF),用于描述微表面法线的分布。相较于传统的Beckmann模型,GGX在处理高粗糙度和极端视角下的反射时表现更佳,能够减少阴影失真和镜面高光过度的问题。
**2. 数学表达**
GGX模型的法线分布函数D如下:
$D_{GGX}(h) = \frac{\alpha^2}{\pi \left[ (\omega \cdot h)^2 (\alpha^2 - 1) + 1 \right]^2}$
其中:
- $\alpha $是粗糙度参数,控制法线分布的宽度。
- $\omega $是表面法线与半程向量$h $的夹角余弦。
**3. 特点与优势**
- **尾部减弱**:相比Beckmann模型,GGX在高粗糙度时能够更好地控制法线分布,避免高光尾部过长的问题。
- **高性能**:GGX的数学形式简洁,易于计算,适合实时渲染应用。
- **物理一致性**:符合能量守恒和其他物理特性,确保反射光的物理真实性。
**4. 应用场景**
- **高粗糙度材质**:在处理粗糙表面如磨砂金属、粗糙塑料时,GGX能够提供更真实的反射效果。
- **实时渲染**:由于其计算效率高,GGX广泛应用于游戏引擎和实时渲染系统中。
**5. PBR中的作用**
GGX作为一种高效且物理准确的法线分布函数,成为PBR中常用的NDF选择。它与Cook-Torrance模型结合使用,能够提供高质量的镜面反射效果,尤其在处理复杂光照和高粗糙度材质时表现出色。
---
### GGX(Trowbridge-Reitz) 细节
在GGX(Trowbridge-Reitz)反射模型中,多个符号用于描述光与材质表面相互作用的各种参数和向量。以下是对这些符号的详细解释:
#### 1. 基本符号
- **$\omega_i$**
入射光方向向量。表示从光源射向表面的光线方向,通常以世界坐标系或局部表面坐标系表示。
- **$\omega_o$**
出射光方向向量。表示从表面反射或折射后向观察者方向传播的光线方向。
- **$h$**
半程向量(Half-Vector)。定义为入射光方向与出射光方向的单位向量之和:
$$
h = \frac{\omega_i + \omega_o}{\|\omega_i + \omega_o\|}
$$
半程向量表示入射光和出射光之间的对称轴方向。
- **$n$**
表面法线向量。表示材质表面的垂直方向,用于确定光线与表面的相对角度。
#### 2. 粗糙度与分布函数
- **$\alpha$**
粗糙度参数。控制表面的微观粗糙度,影响高光的扩散程度。$\alpha$越小,表面越光滑,高光越锐利;$\alpha$越大,表面越粗糙,高光越扩散。
- **$D(h)$**
法线分布函数(Normal Distribution Function, NDF)。描述表面微法线在半程向量方向上的分布密度。GGX模型中的D函数定义为:
$$
D_{GGX}(h) = \frac{\alpha^2}{\pi \left[ (\omega \cdot h)^2 (\alpha^2 - 1) + 1 \right]^2}
$$
其中,$\omega \cdot h$表示法线向量与半程向量的点积,反映了半程向量与表面法线的夹角。
#### 3. 菲涅尔项
- **$F(\omega_i, h)$**
菲涅尔反射项。描述入射光在半程向量方向上的反射比例。通常使用Schlick近似公式计算:
$$
F(\omega_i, h) = F_0 + (1 - F_0) (1 - \omega_i \cdot h)^5
$$
其中,$F_0$是在法线方向上的菲涅尔反射率,表示当入射光与半程向量完全重合时的反射比例。
- **$F_0$**
菲涅尔反射率在法线方向上的值。对于非金属材质,通常由反射率(Albedo)决定;对于金属材质,$F_0$取决于金属的特性。
#### 4. 几何遮挡函数
- **$G(\omega_i, \omega_o)$**
几何遮挡函数(Geometry Function)。描述微表面之间的遮挡关系,考虑了入射光和出射光在表面微结构上的相互遮挡。通常使用Smith几何遮挡函数:
$$
G(\omega_i, \omega_o) = G_1(\omega_i) \cdot G_1(\omega_o)
$$
其中,$G_1(\omega)$为单边几何遮挡函数。
- **$G_1(\omega)$**
单边几何遮挡函数。用于计算单个方向上的遮挡:
$$
G_1(\omega) = \frac{2 (\omega \cdot n)}{\omega \cdot n + \sqrt{\alpha^2 + (1 - \alpha^2)(\omega \cdot n)^2}}
$$
这里,$\omega \cdot n$表示光线方向与表面法线的夹角余弦。
#### 5. 渲染方程相关符号
- **$f_r(\omega_i, \omega_o)$**
双向反射分布函数(BRDF)。描述入射光方向 $\omega_i$和出射光方向 $\omega_o$之间的反射关系。Cook-Torrance模型中的BRDF公式为:
$$
f_r(\omega_i, \omega_o) = \frac{D(h) \cdot F(\omega_i, h) \cdot G(\omega_i, \omega_o)}{4 (\omega_i \cdot n) (\omega_o \cdot n)}
$$
- **$L_o(x, \omega_o)$**
出射辐射度。表示点 $x$朝向方向 $\omega_o$的出射光强度。
- **$L_i(x, \omega_i)$**
入射辐射度。表示点 $x$朝向方向 $\omega_i$的入射光强度。
- **$(\omega_i \cdot n)$**
入射光方向与表面法线的夹角余弦。用于权衡入射光的有效性。
#### 6. 其他符号
- **$\pi$**
数学常数π,约等于3.14159。用于确保能量守恒。
- **$\|\omega_i + \omega_o\|$**
向量的模长(长度)。用于归一化半程向量 $h$。
## [#](#杂项) 杂项
### [#](#billboard有什么作用原理是什么) billboard 有什么作用?原理是什么?
广告牌技术(billboarding)。广告牌技术会根据视角方向来旋转一个被纹理着色的多边形,使得多边形看起来好像总是正对着摄像机。广告牌可以被用于渲染火焰、烟雾、云朵或者闪光,在粒子效果中运用很广泛。
广告牌技术的本质就是构建旋转矩阵,构建一个旋转矩阵需要三个基向量。广告牌技术所使用的基向量通常就是表面法线(固定为视角方向)、指向上的方向以及向右的方向。除此之外一般还需要指定一个锚点 (anchor location) ,这个锚点在旋转过程中是固定不变的,以此来确定多边形在空间中的位置。
### [#](#说一说蒙特卡洛的原理) 说一说蒙特卡洛的原理?
这其实是一种以高效的离散方式对连续的积分求近似的非常直观的方法:对任何面积 / 体积进行积分 —— 例如半球 Ω —— 在该面积 / 体积内生成数量 N 的随机采样,权衡每个样本对最终结果的贡献并求和。
# [#](#c) C++
## constructor(构造函数)
type: Default Constructor, Parameterized Constructor, Copy Constructor, Destructor.
```C++
class Example {
public:
// Default constructor
Example() {
std::cout << "Default" << std::endl;
}
// Parameterized constructor
int x;
Example(int val) {
x = val;
cout << "Parameterized"<< endl;
}
// Copy constructor
Example(const Example &other) {
x = other.x;
std::cout << "Copy constructor called" << std::endl;
}
Example(int val) : x(val) { // Initialization list
std::cout << "initialization list" << std::endl;
}
};
int main() {
Example ex;
Example ex2(10);
Example ex3 = ex2;
}
## singleton
class Singleton {
private:
Singleton() {}
public:
static Singleton& getInstance() {
static Singleton instance; // Guaranteed to be initialized only once (thread-safe in C++11)
return instance;
}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
void showMessage() {
std::cout << "Hello from Singleton!" << std::endl;
}
};
left value and right value (左值和右值)
int left value = right value;
The value we can find after the command have been excuted is left value, otherwise is right value.
left value(locator value)
1 | |
## [#](#smart-pointers) smart pointers
std::unique_ptr: owns the object it points to exclusively. One unique_ptr for a given object at a time. std::move could transfor the ownership(not copy) to the others.
std::unique_ptr<int> uniquePtr(new int(10));
std::shared_ptr: multiple shared pointers to won the same object. There is a counter, the object destroyed when the last ‘shared_ptr’ pointing to it is destoryed or reset.
std::shared_ptr<int> sharedPtr1(new int(20));
std::shared_ptr<int> sharedPtr2 = sharedPtr1; // Both now own the int.
std::weak_ptr: Prevent the memory leak if the counter of shared_ptr never reach zero. ep. A hold a shared_ptr to B, and instances of B hold a shared_ptr to A. Convert weak_ptr to shared_ptr to access the object, ensure it still exists.
std::weak_ptr<int> weakPtr = sharedPtr1; // Does not increase reference count of sharedPtr1's object.
# std::move 实现原理
利用引用折叠原理将右值经过 T&& 传递类型保持不变还是右值,而左值经过 T&& 变为普通的左值引用,以保证模板可以传递任意实参,且保持类型不变;
然后通过 remove_refrence 移除引用,得到具体的类型 T;
最后通过 static_cast<> 进行强制类型转换,返回 T&& 右值引用。
# virtual function
虚函数(virtual function)是一种用于实现多态性(polymorphism)的机制。多态性允许程序在运行时决定调用哪个函数,而不是在编译时确定。虚函数通常在面向对象编程中用于实现基类和派生类之间的动态绑定(dynamic binding)。
基类中使用虚函数,可以在派生类中被覆盖 (override)
虚函数表(Virtual Table):
当类中有虚函数时,编译器会为该类生成一个虚函数表(vtable),其中存储着类的虚函数的地址。每个对象还包含一个指向这个表的指针(vptr)。当调用虚函数时,通过 vptr 找到 vtable,再从 vtable 中找到实际要调用的函数地址。
多态性实现:
使用基类指针或引用指向派生类对象,并通过该指针或引用调用虚函数。Base *b; Derived d; b = &d; b->show(); // 将调用Derived类的show函数# 用途:
实现多态性:允许基类指针调用派生类的重写函数。
动态绑定:在运行时确定函数的调用,而不是在编译时。
接口设计:通过基类定义接口,派生类实现具体功能。
# 小问题
# 虚函数如何实现
虚函数通过虚函数表来实现。虚函数的地址保存在虚函数表中,在类的对象所在的内存空间中,保存了指向虚函数表的指针(称为 “虚表指针”),通过虚表指针可以找到类对应的虚函数表。虚函数表解决了基类和派生类的继承问题和类中成员函数的覆盖问题,当用基类的指针来操作一个派生类的时候,这张虚函数表就指明了实际应该调用的函数。
# 构造函数不能定义为虚函数
构造函数:你要有虚表指针才能找到我!
类:我没有你创建不了虚表指针!
构造函数:你必须先要有对象!!
类:我必须要找到你才能构造对象。。
# 虚函数表存放在哪个内存区?
全局数据区。
# struct(int char)大小,加一个静态变量之后呢?加一个虚函数之后呢?
8 字节(内存对齐),还是 8 字节 (静态变量在全局 / 静态区,static variables are not part of instance size),12 字节(多了一个虚函数表指针(vtable))。
# 创建 10 个实例有几个虚函数表?
1 个,虚函数表数量与实例的对象数量无关。
# 哪些不能是虚函数
构造、内联、静态成员、lamda 函数
`class Base { public: virtual void show() { cout << "Base class show function" << endl; } }; `
覆盖虚函数:
class Derived : public Base { public: void show() override { cout << "Derived class show function" << endl; } };# STL 中常见容器操作时间复杂度小结
map, set, multimap, and multiset 采用红黑树实现,红黑树是平衡二叉树的一种。不同操作的时间复杂度近似为:
* 插入: O (logN)- 查看:O (logN)
- 删除:O (logN)
hash_map, hash_set, hash_multimap, and hash_multiset 采用哈希表实现,不同操作的时间复杂度为:
* 插入:O (1),最坏情况 O (N)。- 查看:O (1),最坏情况 O (N)。
- 删除:O (1),最坏情况 O (N)。
vector 从名字看,随机访问的复杂度应该是 O (1)
* 插入 insert vector O(n)- 插入 push_back vector O(1)
- 删除 pop_back vector O(1)
- 删除 erase vector O(n)
- 查找特点元素的时间复杂度 O(n)
LinkedList 底层是双链表
* get () 获取第几个元素,依次遍历,复杂度 O (n)- add (E) 添加到末尾,复杂度 O (1)
- add (index, E) 添加第几个元素后,需要先查找到第几个元素,直接指针指向操作,复杂度 O (n)
- remove()删除元素,直接指针指向操作,复杂度 O (1)
# map 和 unordered_map 区别
map: map 内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而 AVL 是严格平衡二叉搜索树),红黑树具有自动排序的功能,因此 map 内部的所有元素都是有序的,红黑树的每一个节点都代表着 map 的一个元素。因此,对于 map 进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行的操作。
unordered_map: 内部实现了一个哈希表(也叫散列表,通过把关键码值映射到 Hash 表中一个位置来访问记录,查找的时间复杂度可达到 O (1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。
# 关于 map 容器:优点:
有序性,这是 map 结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
红黑树,内部实现一个红黑树使得 map 的很多操作在 logn 的时间复杂度下就可以实现,因此效率非常的高。
缺点: 空间占用率高(但 map 的空间利用率一般是高于 unordered_map 的),因为 map 内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红 / 黑性质,使得每一个节点都占用大量的空间
适用处:对于那些有顺序要求的问题,用 map 会更高效一些。
# vector 的扩容,哈希表扩容?
vector 的扩容通过一个连续的数组存放元素,如果集合已满,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,再插入新增的元素。根据编译器不同,这个扩大的倍数有所不同,以 GCC 为例,是两倍扩容。
哈希表的扩容和 vector 也很类似,在哈希表中负载因子 = 元素个数 / 散列表长度,当负载因子达到阈值,则需要进行扩容,扩容也是分配更大的散列表,然后进行 rehash,最终再将新元素插入。
# incline 内联函数
是一种特殊的函数类型,它的主要目的是通过在函数调用处直接插入函数代码,以避免函数调用的开销,从而提高程序的执行效率。内联函数是通过在函数定义前加上 inline 关键字来声明的。
当调用内联函数时,编译器会将该函数的代码直接插入到调用点,而不是进行一次函数调用。这可以减少函数调用的开销,特别是对于那些频繁调用的小函数。
减少函数调用开销:通过将函数代码直接插入到调用点,可以避免函数调用的开销,如参数传递、栈帧管理等。
代码膨胀:因为内联函数会在每个调用点插入函数代码,可能会导致生成的可执行文件体积变大。
编译器优化:内联只是对编译器的一个建议,编译器可能会根据具体情况决定是否将函数内联化。如果函数太复杂或太大,编译器可能会忽略 inline 关键字。
# 进程之间如何通信 IPC
pipes : 匿名管道用于在有亲缘关系的进程之间进行通信(通常是父子进程)。它是单向的,即数据只能沿一个方向流动。
FIFO: 命名管道可以在没有亲缘关系的进程之间进行通信。它是一个在文件系统中存在的特殊文件,可以通过文件路径访问。
Message Queues: 消息队列允许进程以消息的形式交换数据,可以在没有亲缘关系的进程之间进行通信。
Shared memory: 共享内存允许多个进程直接访问同一块内存区域,从而实现高速的数据交换。
signals: 信号是一种异步的进程间通信机制,用于通知进程某个事件的发生。
# 内存分布
# 内存分区
global stastic 储存区:存放 global 和 stastic 的变量,程序运行结束 os 自动释放。
const 储存区:存放 const 不可以被修改,程序运行结束自动释放。
代码区:存放代码,不可以修改,但可以执行,编译后的二进制文件放在这里。
C++ 程序在运行时也会按照不同的功能划分不同的段,C++ 程序使用的内存分区一般包括。
# heap (手动)
dynamic 内存分布,意味着内存在运行的时候用 function 来分配或者取消分配的,malloc,calloc,reallco,free,new delete。
内存由程序员手动管理。它可以动态增长和收缩。分配和释放可以按任何顺序发生,从而导致碎片。由于管理空闲内存的开销,与堆栈内存相比,它的访问时间通常较慢。
# stack (自动)
stastic 的内存分布,特别是函数调用管理,局部变量和函数参数
内存通过后进先出 (LIFO) 结构自动管理。
与堆相比,分配和释放内存通常更快,因为此过程遵循严格的顺序(推送和弹出操作)。
堆栈的大小通常是有限的并且小于堆。
它有助于维护函数调用历史记录和局部变量范围。# new 和 malloc
new 在申请内存的同时,会调用对象的构造函数,对象会进行初始化,malloc 仅仅在堆中申请一块指定大小的内存空间,并不会对内存和对象进行初始化。
new 可以指定内存空间初始化对象 (replacement new),而 malloc 只能从堆中申请内存。
new 是 c++ 中的一个操作符,而 malloc 是 C 中的一个函数。
new 内存分配成功,返回该对象类型的指针,分配失败,抛出 bad_alloc 异常;而 malloc 成功申请到内存,返回指向该内存的指针;分配失败,返回 NULL 指针。
new 作为一个运算符可以进行重载,而 malloc 作为一个函数不支持重载。
new 的空间大小由编译器会自动计算,而 malloc 则需要指定空间大小。
# delete 和 free
delete 是 C++ 中的一个操作符,可以进行重载;而 free 是 C 中的一个函数,不能进行重载。
free 只会释放指向的内存,不会执行对象的析构函数;delete 则可以执行对象的析构函数。
# 指针和引用
指针:指针是一个变量,只不过这个变量存储的是一个地址,指向内存的一个存储单元,即指针是一个实体;而引用跟原来的变量实质上是一个东西,只不过是原变量的一个别名而已。
可以有 const 指针,但是没有 const 引用;
指针可以有多级,但是引用只能是一级;
指针的值可以为空,但是引用的值不能为 NULL,并且引用在定义的时候必须初始化;
# 指针常量:
`int * const p = &a; *p = 30; // p指向的地址是一定的,但其内容可以修改 常量指针: `
`const int *p = &a;
p = &b; // 指针可以指向其他地址,但是内容不可以改变
`顶层 const 和底层 const 的概念:顶层 const,本身是 const(指针常量),底层 const(常量指针),指向的对象是 const 的。
# heap vs stack
heap 手动分配用户控制,stack 自动由编译器控制。
heap 手动释放,stack 函数返回自动释放。
heap 慢,由于任意分配和释放会有碎片。stack 由于是后进先出和连续分配内存,速度会更快。
heap 适用于需要动态内存的数据结构,比如 linkedlist,tree。stack 适用于临时变量,或者生命周期只存在于函数内的场景。
# examples
# heap
` #include <iostream> #include <cstdlib> // for malloc and free int main() { // Allocate memory on the heap for an integer int* heapInt = (int*)malloc(sizeof(int)); // Check if the allocation succeeded if (heapInt == nullptr) { std::cerr << "Memory allocation failed!" << std::endl; return 1; } // Assign a value to the allocated memory *heapInt = 42; // Output the value std::cout << "Value stored in heap: " << *heapInt << std::endl; // Free the allocated memory free(heapInt); return 0; } `# stack
`#include <iostream> void stackFunction() { // Allocate memory on the stack for an integer int stackInt = 42; // Output the value std::cout << "Value stored in stack: " << stackInt << std::endl; } int main() { // Call the function that uses stack memory stackFunction(); return 0; } `# 静动态链接库
静态链接:代码在生成可执行文件时,将该程序所需要的全部外部调用函数全部拷贝到最终的可执行程序文件中,在该程序被执行时,该程序运行时所需要的全部代码都会被装入到该进程的虚拟地址空间中
动态链接:代码在生成可执行文件时,该程序所调用的部分程序被放到动态链接库或共享对象的某个目标文件中在程序执行时,当需要调用这部分程序时,操作系统会从将这些动态链或者共享对象进行加载,并将全部内容会被映射到该进行运行的虚拟地址的空间。
二者的优缺点:静态链接浪费空间,每个可执行程序都会有目标文件的一个副本,这样如果目标文件进行了更新操作,就需要重新进行编译链接生成可执行程序(更新困难),优点就是执行的时候运行速度快,因为可执行程序具备了程序运行的所有内容;动态链接节省内存、更新方便,但是动态链接是在程序运行时,每次执行都需要链接,相比静态链接会有一定的性能损失。
# math
点乘(Dot Product)
点乘的公式如下:
$(a, b) = a_x \cdot b_x + a_y \cdot b_y + a_z \cdot b_z$
点乘的应用:
- 角度计算:点乘可以用于计算两个向量之间的夹角。
- 投影:用于将一个向量投影到另一个向量上,在阴影映射和计算向量沿其他向量的分量中有用。
- 背面剔除(Backface Culling):通过观察方向和多边形表面法线的点积,可以判断多边形是否背向相机,如果是,则可以跳过渲染以提高性能。
叉乘(Cross Product)
叉乘的应用:
表面法线计算:在 3D 图形中,叉积用于计算表面法线。渲染 3D 对象时,了解每个点的法线方向对于正确应用光照和着色效果至关重要。例如,一个三角形的三个点可以通过计算边向量的叉积来得到法线:
$ \text{Edge1} = (x_2 - x_1, y_2 - y_1, z_2 - z_1) $
$ \text{Edge2} = (x_3 - x_1, y_3 - y_1, z_3 - z_1) $
$ \text{Normal} = \text{Edge1} \times \text{Edge2} $
方向和旋转:叉积帮助确定对象或摄像机视图的旋转轴。通过生成垂直于给定平面的向量,它可以帮助建立变换对象的旋转矩阵。
动画和绑定:在角色绑定和动画中,叉积确保关节和肢体以正确的方向移动,特别是设置移动约束时。
碰撞检测:叉积帮助确定物体在 3D 空间中的相对方向,在物理计算和碰撞检测系统中十分有用。
UV 映射:对于 3D 模型上的纹理,叉积帮助生成或调整纹理坐标,确保纹理正确地与对象表面对齐。
四元数在图形学中的作用
避免万向锁(Gimbal Lock):欧拉角旋转容易遇到万向锁问题,使得自由度受限。而四元数通过更直接的旋转表示,避免了这个问题。
插值(Slerp 插值):四元数在旋转插值(Spherical Linear Interpolation, Slerp)中非常流畅且稳定,适合平滑过渡和动画效果。
计算效率:四元数表示旋转只需四个数(四元数的四个分量),在复合旋转时计算开销小于矩阵运算,适合实时渲染。
稳定性:四元数不会因旋转叠加而累积误差,从而避免旋转的变形问题,特别适合需要频繁旋转的场景,如角色控制和摄像机旋转。
四元数的旋转公式
给定一个向量 $v$ 和单位四元数 $q$,通过四元数旋转得到的旋转向量 $v’$ 表达式为:
$$
v’ = qvq^*
$$
其中 $q^*$ 为 $q$ 的共轭四元数。这种方式通过四元数的乘法实现旋转,无需构造旋转矩阵。
# [#](#ue5) UE5
## [#](#游戏模式和实例) 游戏模式和实例
GameInstance: 游戏实例,架构凌驾于最顶端,不会随着关卡切换而消失,用于保存临时的全局数据。在 C++ 中用 UGameplayStatic::GetGameInstance () 获取。
GameMode: 设置游戏规则,在地图内生效,比如规定玩家的数量,制定游戏的进入方式,比如 spawn 的生成重生等行为。放在服务端,客户端不能访问。config-defaultEngine.ini-gameMapssettings- globalDefaultGameMode。
DefaultPawn: 角色的外在表现类,包括角色的移动规则,服务端和客户端都存在一份,保持同步。GameMode 中进行修改。
HUD: 屏幕上覆盖的元素基本对象,游戏中每个人类控制的玩家都有自己的 AHUD instance,这个 instance 会覆盖到个人是扣上,只存在于客户端,在 gameMode 中修改。
PlayerController: 拥有 Pawn 并设置他的行为规则,服务器上有所有玩家的 playcontroller,但是本地只有当前玩家的 playercontroller。关联了客户端和服务端,通过该类,可以向服务端发出请求,在 gamemode 中修改。
GameState: 数据的全局管理,服务器和客户端都要存放一份,包括复制到游戏中的客户端的信息,包含游戏分数,比赛是否开始,生成多少 AI 等等,保持数据同步,在 GameMode 中修改。
PlayerState: 角色数据,需要通过 playercontroller 访问,博阿村玩家的信息,比如名字,得分,生命值,对应玩家数据的容器,多人游戏所有玩家的 playerstate 存在于所有机器上,可以从服务器复制到客户端保持同步。
类 客户端 服务器
GameMode —— 存在
DefaultPawn 存在 存在
HUD 存在 不存在
PlayerController 只有当前玩家 拥有所有玩家
GameState 存在 存在
PlayerState 拥有所有玩家 拥有所有玩家# 动态材质实例的作用
动态材质实例 (MID) 是可以在游戏期间(在运行时)进行计算的实例化材质。这表示在游戏期间,您可使用脚本(经过编译的代码或蓝图可视脚本)来更改材质的参数,从而在游戏中改变该材质。这种材质的可能应用场合数不胜数,既可显示不同程度的损坏,也可更改绘图作业以混入不同皮肤纹理来回应面部表情。
# 委托
# 单播委托、多播委托和动态委托的区别
委托是一种泛型但类型安全的方式,可在 C++ 对象上调用成员函数。可使用委托动态绑定到任意对象的成员函数,之后在该对象上调用函数,即使调用程序不知对象类型也可进行操作。
单播委托:只能绑定一个委托函数,绑定的委托函数可以有返回值,可接受不同数量的参数(最多支持 9 个函数参数),委托实例必须绑定在其声明时所定义的同返回类型和参数列表的函数,静态委托执行前最好检查是否绑定,否则会导致程序崩溃,如果重复进行绑定,会覆盖上一次的绑定。
多播委托:拥有大部分与单播委托相同的功能。它们只拥有对对象的弱引用,可以与结构体一起使用,可以四处轻松复制等等。多播委托可以绑定多个委托函数,可以远程加载 / 保存和触发,但多播委托函数不能使用返回值。它们最适合用来四处轻松传递一组委托。多播委托在广播执行时不一定是按照绑定顺序来的,在广播执行时,不需要判断是否绑定了委托函数,直接广播执行即可。
动态委托:动态委托包含动态单播和动态多播,支持蓝图序列化,即可以在蓝图中使用,其函数可按命名查找,但其执行速度比常规委托慢。
委托 可绑定的委托函数 参数 返回值 序列化
单播 一个 支持 支持 不支持
多播 多个 支持 不支持 不支持
动态单播 一个 支持 支持 支持
动态多播 多个 支持 不支持 支持`//单播委托 DECLARE_DELEGATE(FDelegate); //声明 FDelegate Delegate; //定义 Delegate.ExecuteIfBound(); //调用 ActorReference->Delegate.BindUObject(this, &AMyActor::DelegateFunction); //绑定 //多播委托 DECLARE_MULTICAST_DELEGATE(FMulticastDelegate); FMulticastDelegate MulticastDelegate; MulticastDelegate.Broadcast(); ActorReference->MulticastDelegate.AddUObject(this, &AMyActor::MulticastDelegateFunction); //动态单播委托 DECLARE_DYNAMIC_DELEGATE(FDynamicDelegate); FDynamicDelegate DynamicDelegate; DynamicDelegate.ExecuteIfBound(); ActorReference->DynamicDelegate.BindDynamic(this, &AMyActor::DynamicDelegateFunction); //动态多播委托 DECLARE_DYNAMIC_MULTICAST_DELEGATE(FDynamicMulticastDelegate); FDynamicMulticastDelegate DynamicMulticastDelegate; DynamicMulticastDelegate.Broadcast(); ActorReference->DynamicMulticastDelegate.AddDynamic(this, &AMyActor::DynamicMulticastDelegateFunction); `
# 委托的底层原理
委托是一种观察者模式,也被称为代理,用于降低不同对象之间的耦合度,两个有关联的对象不对彼此的行为进行监听,而是通过委托来间接的建立联系,监听者将需要响应的函数绑定到委托对象上,使得委托在触发时调用所绑定的函数。
在 UE 中,委托机制的原理比较简单,就是在委托类的内部保存了函数指针,需要执行这些委托的时候就传入所需的参数给保存的函数指针,从而调用绑定的函数。但实现上稍显复杂,因为要解决两个问题:
需要支持具有任意类型以及数量不限的参数列表的函数
需要支持多种类型函数,如 lambda 匿名函数、C++ 原始成员函数、基于共享指针的成员函数、原始全局函数 (包括静态成员函数)、基于 UFunction 的成员函数、基于 UObject 的成员函数
# 如何保持新建的 UObject 对象不被自动 GC 垃圾回收
在普通的 C++ 类中新建 UObject 对象后,使用 AddToRoot () 函数可以保护对象不被自动回收,移除保护时使用 RemoveFromRoot () 并把对象指针置为 nullptr 即可由引擎自动回收
`UMyObject* MyObject=NewObject<UMyObject>();
MyObject->AddToRoot(); //保护对象不被回收
MyObject->RemoveFromRoot();
MyObject=nullptr; //交给引擎回收对象`
如果是在继承自 UObject 类中新建 UObject 对象后,使用 UPROPERTY 宏标记一下对象指针变量也可以保护对象不被自动回收,在该类被销毁时,新建的对象也会被引擎自动回收;
UCLASS() class UMyObject : public UObject{ GENERATED_BODY() UPROPERTY() class UItemObject* ItemObject; }使用 FStreamableManager 加载资源时,将 bManageActiveHandle 设置为 true 也可以防止对象被回收;
FSoftObjectPath AssetPaths(TEXT("[资源路径]")); FStreamableManager& AssetLoader = UAssetManager::GetStreamableManager(); TSharedPtr<FStreamableHandle> Handle = AssetLoader.RequestSyncLoad(AssetPath, true);//加载资源到内存中,bManageActiveHandle=true UObject* Obj = Handle->GetLoadedAsset(); Handle->ReleaseHandle();//从内存中释放资源FGCObjectScopeGuard 在指定代码区域内保持对象;
{ FGCObjectScopeGuard(UObject* GladOS = NewObject<...>(...)); GladOS->SpawnCell(); RunGC(); GladOS->IsStillAlive(); }# UE5 中的智能指针
共享指针(TSharedPtr)允许多个该类型的指针指向同一块内存,采用引用计数器的方式,统计所有指向同一块内存的指针变量的数量,当新的指针变量生命初始化并指向同一块内存,拷贝函数拷贝和赋值操作时引用计数器会自增加,当指针变量生命周期结束调用析构函数时,引用计数器会自减少。引用计数器减少至 0 时,释放指向的内存。共享引用(TShareRef)和共享指针的区别是共享指针可以为 NULL,而共享引用不能为 NULL 。
弱指针(TWeakPtr
TSharedPtr)主要是为了配合共享指针而引入的一种智能指针,TWeakPtr 没有指针的行为,没有重载间接引用操作符 (->) 和解除引用操作符 (*),它可以通过 TSharedPtr 和 TSharedRef 来初始化,但只引用,不计数,不拥有内存的所有权,不会对 TSharedPtr 和 TSharedRef 的共享引用计数器产生影响,也不影响其生命周期,但会在控制块的 WeakReferenceCount 属性中统计弱指针引用数量。唯一指针(TUniquePtr)仅会显式拥有其引用的对象。仅有一个唯一指针指向给定资源,因此唯一指针可转移所有权,但无法共享。复制唯一指针的任何尝试都将导致编译错误。唯一指针超出范围时,其将自动删除其所引用的对象。
`TSharedPtr<Person> sp = MakeShared<Person>(); //创建共享指针 TSharedRef<Person> sr = sp.ToSharedRef(); //创建共享引用 TWeakPtr<Person> wp = sp; //创建弱指针 int32 use_count = sp.GetSharedReferenceCount(); //共享指针计数 TUniquePtr<Person> up = MakeUnique<Person>(); //创建唯一指针 `
# 智能指针的循环引用
在使用基于引用计数的 TSharedPt r 智能指针时,为了防止循环引用带来的内存泄漏问题,可以让引用链上的一方持用弱智能指针 TWeakPtr 。弱智能指针不会影响共享引用计数器。
# 如何使用 ParallelFor 提高速度
ParallelFor 允许我们在一分钟内对任何 for 循环进行多线程处理,从而通过在多个线程之间拆分工作来划分执行时间。
`//例1 ParallelFor(num, [&](int32 i) {sum += i; }); //例2 FCriticalSection Mutex; ParallelFor(Input.Num(), [&](int32 Idx){ if(Input[Idx] % 5 == 0){ Mutex.Lock(); Output.Add(Input[Idx]); Mutex.Unlock(); } }); `# TMap 的实现原理
TMap 是用基于数组的哈希表实现的,查询效率高,添加、删除效率低,查询的时间复杂度是
O (1) TMap 的排序采用的快速排序 , 时间复杂度为数据结构 查询时间复杂度 优点 缺点
map 红黑树 O (logn) 内部自动排序,查询、添加、删除效率相同 空间占用较大
unordered_map 哈希表 O (1) 查询效率高 内部元素无序杂乱添加、删除效率低
TMap 哈希表 O (1) 查询效率高 内部元素无序杂乱添加、删除效率低# 虚幻中有哪几种主要线程
游戏线程(GameThread):承载游戏逻辑、运行流程的工作,也是其它线程的数据发起者。在 FEngineLoop::Tick 函数执行每帧逻辑的更新。在引擎启动时会把 GameThread 的线程 id 存储到全局变量 GGameThreadId 中,且稍后会设置到 TaskGraph 系统中。
渲染线程(RenderThread):RenderThread 在 TaskGraph 系统中有一个任务队列,其他线程(主要是 GameThread)通过宏 ENQUEUE_RENDER_COMMAND 向该队列中填充任务,RenderThread 则不断从这个队列中取出任务来执行,从而生成与平台无关的 Command List(渲染指令列表)。
RHI 线程(Render Hardware Interface Thread):RenderThread 作为前端(frontend)产生的 Command List 是平台无关的,是抽象的图形 API 调用;而 RHIThread 作为后端(backend)会执行和转换渲染线程的 Command List 成为指定图形 API 的调用(称为 Graphical Command),并提交到 GPU 执行。RHI 线程的工作是转换渲染指令到指定图形 API,创建、上传渲染资源到 GPU。
# 游戏线程和渲染线程的同步
当 GameThread 与 RenderThread 同步时,GameThread 会创建一个 FNullGraphTask 空任务,放到 RenderThread 的 TaskGraph 队列中让其执行,在 FRenderCommandFence 的 Wait 函数中,会检查投递给 RenderThread 的 CompletionEvent 是否被执行,如果没有执行则调用 GameThreadWaitForTask 函数来阻塞等待。
# 多线程 Task Graphß
TaskGraph 是 UE 中基于任务的并发机制。可以创建任务在指定类型的线程中执行,同时提供了等待机制,其强大之处在于可以调度一系列有依赖关系的任务,这些任务组成了一个有向无环的任务网络(DAG),并且任务的执行可以分布在不同的线程中。
`void ATestTaskGraphActor::CreateTask(FString TaskName, const TArray<TGraphTask<FWorkTask>*>& Prerequisites, const TArray<TGraphTask<FWorkTask>*>& ChildTasks){ //FWorkTask为自定义的类 FGraphEventArray PrerequisiteEvents; TArray<TGraphTask<FWorkTask>*> ChildEvents; for (auto Item : Prerequisites) PrerequisiteEvents.Add(Item->GetCompletionEvent()); for (auto Item : ChildTasks) ChildEvents.Add(Item); TGraphTask<FWorkTask>::CreateTask(&PrerequisiteEvents).ConstructAndDispatchWhenReady(TaskName, ChildEvents, this); } `# 后处理
# 后处理之泛光(Bloom)
是一种现实世界中的光现象,通过它能够以较为适度的渲染性能成本极大地增加渲染图像的真实感。用肉眼观察黑暗背景下非常明亮 的物体时会看到泛光效果。泛光可以用一个高斯模糊来实现。为了提高质量,我们将多个不同半径的高斯模糊组合起来。为了获得更好的性能,我们在大大降低的分辨率下进行很宽范围的模糊。通过改变模糊效果的组合方式,我们可以进行更多的控制,取得更高的质量。为了获得最佳的性能,应该使用高分辨率模糊(小值)来实现较窄的模糊,而主要使用低分辨率模糊 (大值)实现较宽的模糊。
# 后处理之轮廓描边
对需要描边的物体开启自定义深度缓存,物体所在区域会出现填充的具有深度信息的缓存区,通过后期处理对相邻像素进行采样来执行简单的深度比较,如果邻居有深度信息,但像素没有,就将其着色为轮廓线颜色
获取场景法线向量后,通过其中一个做一点点 UV 偏移,是两个结果做差,颜色值越接近,插值越小,相反越大,而一般需要描边的位置就是向量相差较大的像素点,再用基础颜色加上这个差值就会出现描边效果。
# 蓝图大量连线为何会比 C++ 慢很多
蓝图的消耗主要是在节点之间,蓝图连线触发的消耗是一致的,但节点运行的消耗是通过 C++ , 节点不同就有所不同 ,所以蓝图中连线很多时会显著降低运行效率。
# 模型闪烁问题如何解决
当两个面共面时,会出现闪面现象。使用 UE4 材质中 Pixel Depth Offset 节点,进行像素偏移,达到共面不闪面的效果。
# slate 中常用的控件
既能用于 Runtime 中的 UI,也能用于 Edit 状态下的操作界面创建,其强大的功能能满足你各种复杂的需求
SHorizontalBox:水平框SVerticalBox:垂直框
SUniformGridPanel:统一网格面板,均匀地垂直和水平分发子控件的面板
SWrapBox:包围盒,水平排列控件的盒
# 反射的作用
反射实现来支持引擎的动态功能,如垃圾回收、序列化、网络复制和蓝图 / C++ 通信等。
# 结构体中是否可以使用 UFUNCTION ()
不可以。反射系统不支持结构体中的函数,即使在 C++ 类和结构中实际上也具有与类相同的功能,UE4 约定将结构限制为仅包含数据结构,这种做法实际上赋予结构更多的存在感。
# UE 中垃圾回收的原理
UE4 采用了标记 - 清扫的垃圾回收方式,是一种经典的垃圾回收方式。一次垃圾回收分为两个阶段。第一阶段从一个根集合出发,遍历所有可达对象,遍历完成后就能标记出可达对象和不可达对象了,这个阶段会在一帧内完成。第二阶段会渐进式的清理这些不可达对象,因为不可达的对象将永远不能被访问到,所以可以分帧清理它们,避免一下子清理很多 UObject,比如 map 卸载时,发生明显的卡顿。
# UE 中有哪几种容器
TArray:是 UE4 中最常用的容器类,负责同类型其他对象(称为 "元素")序列的所有权和组织。由于 TArray 是一个序列,其元素的排序定义明确,其函数用于确定性地操纵此类对象及其顺序。
TMap:继 TArray 之后,UE4 中最常用的容器是 TMap。TMap 主要由两个类型定义(一个键类型和一个值类型),以关联对的形式存储在映射中。与 TSet 类似,它们的结构均基于对键进行散列运算。但与 TSet 不同的是,此容器将数据存储为键值对(TPair<KeyType, ValueType>),只将键用于存储和获取。
TSet:是一种快速容器类,(通常)用于在排序不重要的情况下存储唯一元素。TSet 类似于 TMap 和 TMultiMap,但有一个重要区别:TSet 是通过对元素求值的可覆盖函数,使用数据值本身作为键,而不是将数据值与独立的键相关联。TSet 可以非常快速地添加、查找和删除元素(恒定时间)。默认情况下,TSet 不支持重复的键,但使用模板参数可激活此行为。
# gameplay 的框架
UE 的游戏世界构成层级为:
GameInstance:游戏实例,由 GameEngine 创造出来,主要用于管理世界切换,UI 的加载,控制台命令和额外的逻辑,初始化 / 关闭引擎,修改 GameMode,在线会话管理等一些全局性的内容。
World:游戏世界,常用结构体 FWorldContext 记录了游戏世界的各种信息使用在游戏世界切换等功能。
Level:一个游戏世界,可以分成多个 Level,比如将游戏场景分成一个 Level,灯光分成一个 Level 等等,这样有利于美术师进行场景搭建。关卡也分为 Persistence Level 和 Streaming Level,Persistence Level 是建立我们世界的主 Level,Streaming Level 是作为部分内容的 Level 按照我们定义的规则加载到 Persistence Level 里。
GameMode:定义游戏规则,存在于每个 World/Level 中,并且只在服务器上,通过 GameState 来传递信息。
Actor:所有能放到游戏场景中的对象的基类都是 AActor。
Component:表现 Actor 的各种构成部分,UE 中的 Component 类能够附加到 Actor 上。
Gameplay 的 3C 概念,就是 Character、Camera、Control。Character 表现游戏世界中的玩家,拥有游戏世界中最复杂的行为,对于程序员来说,要负责处理角色的移动,动画,皮肤(装备)等。Camera 处理游戏视角,表现游戏世界,第一人称,第三人称,FOV,VFX,后处理,抖动等。Control 处理输入(来自鼠标键盘,手柄,模拟器等,以及输入模式例如单击、按住、双击),匹配输入逻辑(按键映射),处理回应输入的逻辑,UI 交互,以及物理模拟,AI 驱动等。# Unreal 中使用的光线追踪方法有哪些
Ray Traced Reflections 反射。这种方法可以生成准确的反射,包括多重反射,即反射中的反射。它比传统的屏幕空间反射(Screen Space Reflections, SSR)提供了更广阔的视野和更高的准确性,因为它不仅限于屏幕上已渲染的信息。
Ray Traced Refractions 折射。 用于透明和半透明材质,如玻璃,水等,提供更真实的光线折射效果。
Ray Traced Shadows: 提供更精确的软阴影效果。它能够处理复杂的光线遮挡关系,包括透明度遮挡和细微阴影细节。
Ray Traced Ambient Occlusion: 增强了环境光遮挡的效果,提供更真实的局部阴影,尤其是在物体相互靠近的地方。
Ray Traced Global Illumination: 用于计算场景的间接照明,比传统的全局照明技术如光照贴图或屏幕空间的间接照明提供更真实的光照效果。
Ray Traced Translucency: 允许更真实地渲染半透明材料,如皮肤、蜡、叶子等
# 计算机网络
# 网络协议 (network protocol) 为什么要对网络协议分层
网络协议是计算机在通信过程中要遵循的一些约定好的规则。
网络分层的原因:易于实现和维护,因为各层之间是独立的,层与层之间不会收到影响。
有利于标准化的制定# 各层协议的作用
OSI 七层模型:应用层,表示层,会话层,运输层,网络层,数据链路层,物理层
TCP/IP: 应用层,运输层,网络层,网络接口层
五层协议:应用层,运输层,网络层,数据链路层,物理层
应用层
应用层的任务是通过应用进程之间的交互来完成特定的网络作用,常见的应用层协议有域名系统 DNS,HTTP 协议等。表示层
表示层的主要作用是数据的表示、安全、压缩。可确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。会话层
会话层的主要作用是建立通信链接,保持会话过程通信链接的畅通,同步两个节点之间的对话,决定通信是否被中断以及通信中断时决定从何处重新发送。。传输层
传输层的主要作用是负责向两台主机进程之间的通信提供数据传输服务。传输层的协议主要有传输控制协议 TCP 和用户数据协议 UDP。网络层
网络层的主要作用是选择合适的网间路由和交换结点,确保数据及时送达。常见的协议有 IP 协议。
数据链路层
数据链路层的作用是在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列。 常见的协议有 SDLC、HDLC、PPP 等。物理层
物理层的主要作用是实现相邻计算机结点之间比特流的透明传输,并尽量屏蔽掉具体传输介质和物理设备的差异。# URI 和 URL 的区别
URI (Uniform Resource Identifier):中文全称为统一资源标志符,主要作用是唯一标识一个资源。
URL (Uniform Resource Location):中文全称为统一资源定位符,主要作用是提供资源的路径。
有个经典的比喻是 URI 像是身份证,可以唯一标识一个人,而 URL 更像一个住址,可以通过 URL 找到这个人。# TCP 与 UDP 的区别

TCP 是一种面向连接的协议,意味着在数据传输开始之前,必须先建立连接。TCP 通过三次握手过程建立连接,确保双方都准备好接收和发送数据。
UDP 是一种无连接的协议,发送数据之前不需要建立连接。这使得 UDP 的速度通常比 TCP 快,但也更不可靠。TCP 提供可靠的数据传输,通过序号、确认应答、重传机制等确保数据的正确顺序和完整性。如果发现数据丢失或错误,TCP 会自动重传丢失的数据包。
UDP 不保证数据的可靠性或顺序,接收端收到数据的顺序可能与发送顺序不同,且丢失的数据包不会被重传。TCP 适用于要求高可靠性的应用,如网页浏览、文件传输、电子邮件等。
UDP 通常用于对实时性要求较高的应用,如视频流、VoIP(网络电话)、在线游戏等,这些应用可以容忍一定程度的数据丢失,但需要高速传输。简而言之,TCP 更注重数据的可靠传输,而 UDP 则更注重传输效率。根据不同的应用需求选择合适的协议非常重要。
# TCP 三次握手
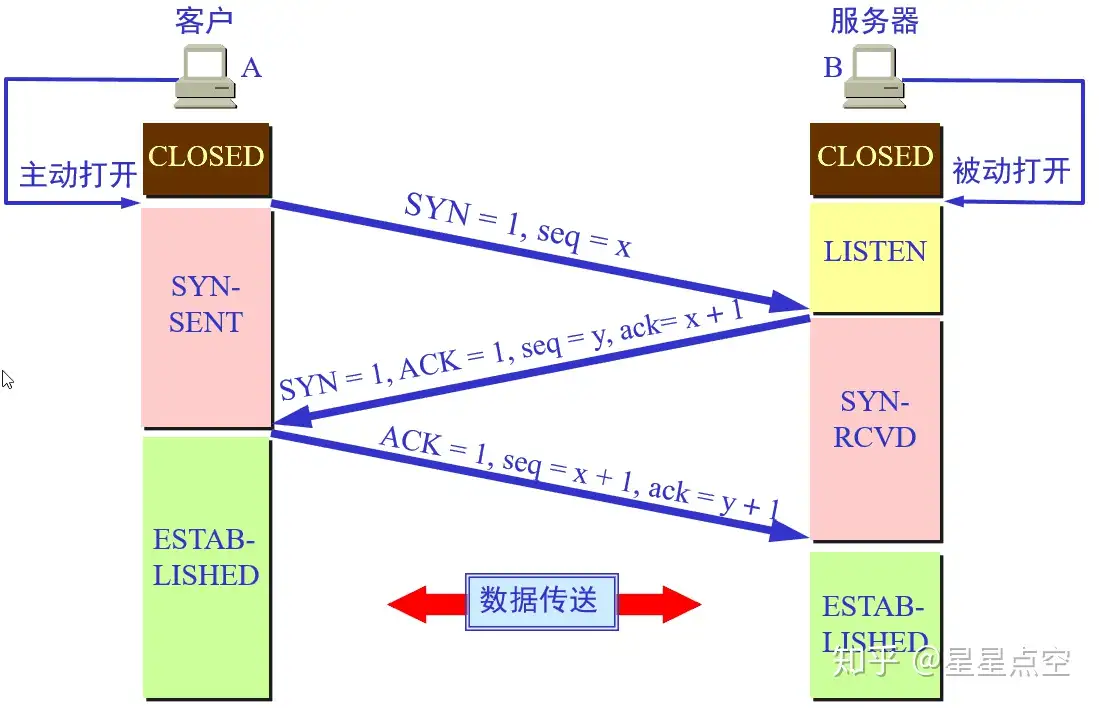
seq: 序号:seq,占 32 位,用来标识从发送端到接收端发送的字节流。
ack: 确认号:ack,占 32 位,只有 ACK 标志位为 1 时,确认序号字段才有效,ack=seq+1。
SYN: 标志位:SYN:发起一个新连接。
FIN:释放一个连接。
ACK:确认序号有效。
# graphic card
# cpu 与 gpu 的区别?
CPU 的设计着重于处理单个线程的复杂计算和控制流程。
GPU 被设计用于高密度和并行计算,更多的晶体管投入到数据处理而不是数据缓存和流量控制
体现在 GPU 的 ALU(算术逻辑运算单元)数量更多# ALU, 全称是算术逻辑单元(Arithmetic Logic Unit)
,是计算机处理器(CPU)和其他数字电路中的一个关键组件。它主要负责执行所有的算术和逻辑运算。以下是 ALU 的一些主要功能:
算术运算:包括加法、减法、乘法和除法。
逻辑运算:包括与(AND)、或(OR)、非(NOT)和异或(XOR)等逻辑操作。
移位操作:包括左移、右移等位移操作。
比较操作:包括大于、小于、等于等比较运算。
在现代计算机系统中,ALU 通常与控制单元(Control Unit)和寄存器(Registers)等其他组件一起工作,构成了中央处理单元(CPU)的核心部分。ALU 接收来自寄存器或内存的数据,根据控制单元的指令执行相应的运算,并将结果存储回寄存器或内存中。# cuda
`#include <stdio.h> #include <cuda_runtime.h> // CUDA 内核函数,在 GPU 上执行 __global__ void vectorAdd(float *a, float *b, float *c, int n) { int i = blockDim.x * blockIdx.x + threadIdx.x; if (i < n) { c[i] = a[i] + b[i]; } } int main() { int n = 1 << 20; // 向量大小(1,048,576) size_t size = n * sizeof(float); // 在主机(CPU)上分配内存 float *h_a = (float *)malloc(size); float *h_b = (float *)malloc(size); float *h_c = (float *)malloc(size); // 初始化向量 for (int i = 0; i < n; i++) { h_a[i] = 1.0f; h_b[i] = 2.0f; } // 在设备(GPU)上分配内存 float *d_a, *d_b, *d_c; cudaMalloc((void **)&d_a, size); cudaMalloc((void **)&d_b, size); cudaMalloc((void **)&d_c, size); // 将数据从主机复制到设备 cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice); cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice); // 定义执行配置 int blockSize = 256; int numBlocks = (n + blockSize - 1) / blockSize; // 启动 CUDA 内核 vectorAdd<<<numBlocks, blockSize>>>(d_a, d_b, d_c, n); // 将结果从设备复制到主机 cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost); // 验证结果 for (int i = 0; i < n; i++) { if (h_c[i] != 3.0f) { printf("Error at index %d: %f\n", i, h_c[i]); break; } } printf("Vector addition completed successfully.\n"); // 释放内存 free(h_a); free(h_b); free(h_c); cudaFree(d_a); cudaFree(d_b); cudaFree(d_c); return 0; }
# cuda 编程中的 SM SP 是什么
SP (streaming processor), 计算核心,最基本处理单元
SM (Streaming multiprocessor), 多个 SP 加上其他找资源组成一个 SM
# CUDA 编程的内存模型
- 全局内存(Global Memory)
描述:全局内存是 GPU 上的主要内存空间,所有线程块(blocks)中的所有线程都可以访问。
特点:
高延迟,但大容量。
访问时需要进行内存协作以提高性能(如合并访问)。
用于存储在不同线程块之间共享的数据或大数据集。
使用:通过 CUDA API 函数如 cudaMalloc 和 cudaMemcpy 分配和管理。 - 共享内存(Shared Memory)
描述:共享内存是每个线程块中的所有线程可以访问的快速内存空间。它是按线程块划分的,每个线程块都有自己的共享内存。
特点:
低延迟,比全局内存更快。
小容量,但可用作线程块内部的数据共享和缓存。
可以通过 CUDA 内核中的 shared 关键字声明。
使用:适合需要在同一线程块中多个线程共享和频繁访问的数据。 - 寄存器(Registers)
描述:寄存器是每个线程私有的快速存储器,用于存储线程的局部变量。
特点:
非常低的延迟,最快的内存。
每个线程有一个固定数量的寄存器,数量有限。
由编译器自动分配。
使用:适合存储局部变量和频繁访问的数据。
# CUDA 编程的软件模型
- 线程(Thread)
描述:线程是 CUDA 程序的基本执行单元。每个线程在 GPU 上独立执行一段代码(内核函数)。
特点:
每个线程都有自己的寄存器和本地内存。
线程在块(block)中组织,并由块索引(blockIdx)和线程索引(threadIdx)唯一标识。
通过内核函数中的 threadIdx 和 blockIdx 获取索引。 - 线程块(Thread Block)
描述:线程块是一组可以共享共享内存和同步的线程。每个线程块中的线程数量和结构在内核启动时指定。
特点:
每个线程块可以包含最多 1024 个线程(具体数量取决于 GPU 硬件)。
线程块可以在不同的流式多处理器(SM)上独立执行。
线程块内的线程可以使用 __syncthreads () 进行同步。 - 线程格(Grid)
描述:线程格是由多个线程块组成的结构,用于表示并行任务的总大小。每次启动一个内核函数时,会创建一个线程格。
特点:
线程格中的所有线程块可以独立执行。
线程格的大小在内核启动时指定,使用 dim3 结构定义。
线程格可以是一维、二维或三维的。
# 使用共享内存时需要注意什么?
# 线程同步
__syncthreads() 在利用共享内存进行线程块之间合作通信前,都要进行同步,以确保共享内存变量中的数据对线程块内的所有线程来说都准备就绪
# 避免共享内存的 bank 冲突
bank 冲突概念:同一线程束内的多个线程试图访问同一个 bank 中不同层的数据时,造成 bank 冲突
只要同一线程束内的多个线程不同时访问同一个 bank 中不同层的数据,该线程束对共享内存的访问就只需要一次内存事务
# ROCm
ROCm(Radeon Open Compute)是 AMD 提供的开源高性能计算(HPC)和机器学习平台,旨在支持在 AMD GPU 上进行并行计算和加速计算。ROCm 提供了一套软件工具和库,使开发者能够利用 AMD GPU 的强大计算能力。以下是 ROCm 的主要组件和特点的介绍:
# 显卡驱动
# 驱动程序架构
- 内核模式驱动程序(Kernel-Mode Driver):
直接与 GPU 硬件交互。
负责硬件初始化、内存管理、上下文切换和硬件中断处理。
在 Windows 上,称为 AMD KMD(Kernel Mode Driver)。
在 Linux 上,通常是开源的 AMDGPU 驱动程序。
- 用户模式驱动程序(User-Mode Driver):
运行在用户空间,与操作系统的图形子系统和应用程序交互。
提供图形 API 支持,如 DirectX、OpenGL 和 Vulkan。
负责图形命令的处理、着色器编译和优化。
# 驱动程序组件
- 显示驱动程序(Display Driver):
负责显示输出管理,包括屏幕分辨率设置、刷新率调整和多显示器支持。
处理与操作系统的窗口管理系统的交互。
- 计算驱动程序 (Compute Driver):
提供对通用计算 API 的支持,如 OpenCL 和 ROCm。
允许使用 GPU 进行高性能计算任务,如科学计算、机器学习和数据分析。
- 多媒体驱动程序(Multimedia Driver):
支持视频编码和解码加速(如 H.264、H.265)。
处理多媒体应用程序的图像处理和视频播放任务。
# papers
最近读的 paper
- Adjoint-Driven Russian Roulette and Splitting in Light Transport Simulation.
- Generalizing Shallow Water Simulations with Dispersive Surface Waves.
-
1. [<span class="toc-number">1.1.</span> <span class="toc-text">graphic pipeline</span>](#graphic-pipeline) 1. [<span class="toc-number">1.1.1.</span> <span class="toc-text">Application 配置基础信息</span>](#application-%E9%85%8D%E7%BD%AE%E5%9F%BA%E7%A1%80%E4%BF%A1%E6%81%AF) 2. [<span class="toc-number">1.1.2.</span> <span class="toc-text">空间加速算法 (Spatial Acceleration)</span>](#%E7%A9%BA%E9%97%B4%E5%8A%A0%E9%80%9F%E7%AE%97%E6%B3%95spatial-acceleration) 1. [<span class="toc-number">1.1.2.1.</span> <span class="toc-text">spatial partition vs object partition</span>](#spatial-partition-vs-object-partition) 2. [<span class="toc-number">1.1.2.2.</span> <span class="toc-text">基于空间 (spatial partition)</span>](#%E5%9F%BA%E4%BA%8E%E7%A9%BA%E9%97%B4spatial-partition) 3. [<span class="toc-number">1.1.2.3.</span> <span class="toc-text">基于物体</span>](#%E5%9F%BA%E4%BA%8E%E7%89%A9%E4%BD%93) 3. [<span class="toc-number">1.1.3.</span> <span class="toc-text">视锥剔除 (View frustum culling)</span>](#%E8%A7%86%E9%94%A5%E5%89%94%E9%99%A4view-frustum-culling)-
1. [<span class="toc-number">1.2.1.</span> <span class="toc-text">顶点着色器(Vertex Shader):</span>](#%E9%A1%B6%E7%82%B9%E7%9D%80%E8%89%B2%E5%99%A8vertex-shader) 1.4. 光照模型 (illumination model)
1. [<span class="toc-number">1.4.1.</span> <span class="toc-text">局部光照模型 (local illumination model)</span>](#%E5%B1%80%E9%83%A8%E5%85%89%E7%85%A7%E6%A8%A1%E5%9E%8Blocal-illumination-model)-
1. [<span class="toc-number">1.7.1.</span> <span class="toc-text">forward rendering</span>](#forward-rendering) -
1. [<span class="toc-number">1.8.1.</span> <span class="toc-text">CSM:</span>](#csm) -
1. [<span class="toc-number">1.9.1.</span> <span class="toc-text">PBR 概念</span>](#pbr%E6%A6%82%E5%BF%B5)-
1. [<span class="toc-number">1.9.5.1.</span> <span class="toc-text">1. Albedo(反照率)</span>](#1-albedo%E5%8F%8D%E7%85%A7%E7%8E%87) -
1. [<span class="toc-number">1.9.7.1.</span> <span class="toc-text">Cook-Torrance 模型的优点</span>](#cook-torrance-%E6%A8%A1%E5%9E%8B%E7%9A%84%E4%BC%98%E7%82%B9)
-
1. [<span class="toc-number">1.10.1.</span> <span class="toc-text">MVP 矩阵公式推导</span>](#mvp-%E7%9F%A9%E9%98%B5%E5%85%AC%E5%BC%8F%E6%8E%A8%E5%AF%BC) -
1. [<span class="toc-number">1.11.1.</span> <span class="toc-text">合并几何体(Geometry Merging)</span>](#%E5%90%88%E5%B9%B6%E5%87%A0%E4%BD%95%E4%BD%93geometry-merging)
2. [<span class="toc-number">1.11.2.</span> <span class="toc-text">实例化渲染(Instanced Rendering)</span>](#%E5%AE%9E%E4%BE%8B%E5%8C%96%E6%B8%B2%E6%9F%93instanced-rendering) 3. [<span class="toc-number">1.11.3.</span> <span class="toc-text">使用纹理图集(Texture Atlas)</span>](#%E4%BD%BF%E7%94%A8%E7%BA%B9%E7%90%86%E5%9B%BE%E9%9B%86texture-atlas) 4. [<span class="toc-number">1.11.4.</span> <span class="toc-text">批处理(Batching)</span>](#%E6%89%B9%E5%A4%84%E7%90%86batching) 5. [<span class="toc-number">1.11.5.</span> <span class="toc-text">动态管理资源(Dynamic Resource Management)</span>](#%E5%8A%A8%E6%80%81%E7%AE%A1%E7%90%86%E8%B5%84%E6%BA%90dynamic-resource-management) 6. [<span class="toc-number">1.11.6.</span> <span class="toc-text">使用多重索引缓冲区(Multi-Index Buffers)</span>](#%E4%BD%BF%E7%94%A8%E5%A4%9A%E9%87%8D%E7%B4%A2%E5%BC%95%E7%BC%93%E5%86%B2%E5%8C%BAmulti-index-buffers) 7. [<span class="toc-number">1.11.7.</span> <span class="toc-text">减少状态改变(State Changes)</span>](#%E5%87%8F%E5%B0%91%E7%8A%B6%E6%80%81%E6%94%B9%E5%8F%98state-changes) 8. [<span class="toc-number">1.11.8.</span> <span class="toc-text">使用更高效的资源绑定方式</span>](#%E4%BD%BF%E7%94%A8%E6%9B%B4%E9%AB%98%E6%95%88%E7%9A%84%E8%B5%84%E6%BA%90%E7%BB%91%E5%AE%9A%E6%96%B9%E5%BC%8F)-
1. [<span class="toc-number">1.12.1.</span> <span class="toc-text">billboard 有什么作用?原理是什么?</span>](#billboard%E6%9C%89%E4%BB%80%E4%B9%88%E4%BD%9C%E7%94%A8%E5%8E%9F%E7%90%86%E6%98%AF%E4%BB%80%E4%B9%88)
2. [<span class="toc-number">1.12.2.</span> <span class="toc-text">说一说蒙特卡洛的原理?</span>](#%E8%AF%B4%E4%B8%80%E8%AF%B4%E8%92%99%E7%89%B9%E5%8D%A1%E6%B4%9B%E7%9A%84%E5%8E%9F%E7%90%86) -
-
1. [<span class="toc-number">2.1.</span> <span class="toc-text">smart pointers</span>](#smart-pointers) 1. [<span class="toc-number">2.1.1.</span> <span class="toc-text">std::move 实现原理</span>](#stdmove%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86)-
1. [<span class="toc-number">2.2.1.</span> <span class="toc-text">用途:</span>](#%E7%94%A8%E9%80%94)-
1. [<span class="toc-number">2.2.2.1.</span> <span class="toc-text">虚函数如何实现</span>](#%E8%99%9A%E5%87%BD%E6%95%B0%E5%A6%82%E4%BD%95%E5%AE%9E%E7%8E%B0)
-
-
1. [<span class="toc-number">2.4.0.1.</span> <span class="toc-text">关于 map 容器:优点:</span>](#%E5%85%B3%E4%BA%8Emap%E5%AE%B9%E5%99%A8%E4%BC%98%E7%82%B9)
-
-
1. [<span class="toc-number">2.8.1.</span> <span class="toc-text">内存分区</span>](#%E5%86%85%E5%AD%98%E5%88%86%E5%8C%BA)-
1. [<span class="toc-number">2.8.6.1.</span> <span class="toc-text">指针常量:</span>](#%E6%8C%87%E9%92%88%E5%B8%B8%E9%87%8F) -
1. [<span class="toc-number">2.8.8.1.</span> <span class="toc-text">heap</span>](#heap)
- 3. math
- 4. UE5
-
1. [<span class="toc-number">4.3.1.</span> <span class="toc-text">单播委托、多播委托和动态委托的区别</span>](#%E5%8D%95%E6%92%AD%E5%A7%94%E6%89%98-%E5%A4%9A%E6%92%AD%E5%A7%94%E6%89%98%E5%92%8C%E5%8A%A8%E6%80%81%E5%A7%94%E6%89%98%E7%9A%84%E5%8C%BA%E5%88%AB) -
1. [<span class="toc-number">4.4.1.</span> <span class="toc-text">智能指针的循环引用</span>](#%E6%99%BA%E8%83%BD%E6%8C%87%E9%92%88%E7%9A%84%E5%BE%AA%E7%8E%AF%E5%BC%95%E7%94%A8) -
1. [<span class="toc-number">4.7.1.</span> <span class="toc-text">游戏线程和渲染线程的同步</span>](#%E6%B8%B8%E6%88%8F%E7%BA%BF%E7%A8%8B%E5%92%8C%E6%B8%B2%E6%9F%93%E7%BA%BF%E7%A8%8B%E7%9A%84%E5%90%8C%E6%AD%A5) -
1. [<span class="toc-number">4.9.1.</span> <span class="toc-text">后处理之泛光(Bloom)</span>](#%E5%90%8E%E5%A4%84%E7%90%86%E4%B9%8B%E6%B3%9B%E5%85%89bloom) - 5. 计算机网络
5.1. 网络协议 (network protocol) 为什么要对网络协议分层
1. [<span class="toc-number">5.1.1.</span> <span class="toc-text">各层协议的作用</span>](#%E5%90%84%E5%B1%82%E5%8D%8F%E8%AE%AE%E7%9A%84%E4%BD%9C%E7%94%A8)-
1. [<span class="toc-number">5.3.1.</span> <span class="toc-text">TCP 三次握手</span>](#tcp-%E4%B8%89%E6%AC%A1%E6%8F%A1%E6%89%8B)</li><li class="toc-item toc-level-1">[<span class="toc-number">6.</span> <span class="toc-text">graphic card</span>](#graphic-card) - 6.1. cuda
- 6.2. CUDA 编程的软件模型
-
1. [<span class="toc-number">6.2.1.1.</span> <span class="toc-text">线程同步</span>](#%E7%BA%BF%E7%A8%8B%E5%90%8C%E6%AD%A5) - 7. papers
*****
算法
排序
Bubble sort
相邻元素两两比较,大的交换到后面,逐步将最大的数移到末尾
Selection Sort
每次从未排序部分中选择最小的元素,放到已排序部分的末尾。
Insertion Sort
从未排序部分中取出一个元素,插入到已排序部分的合适位置